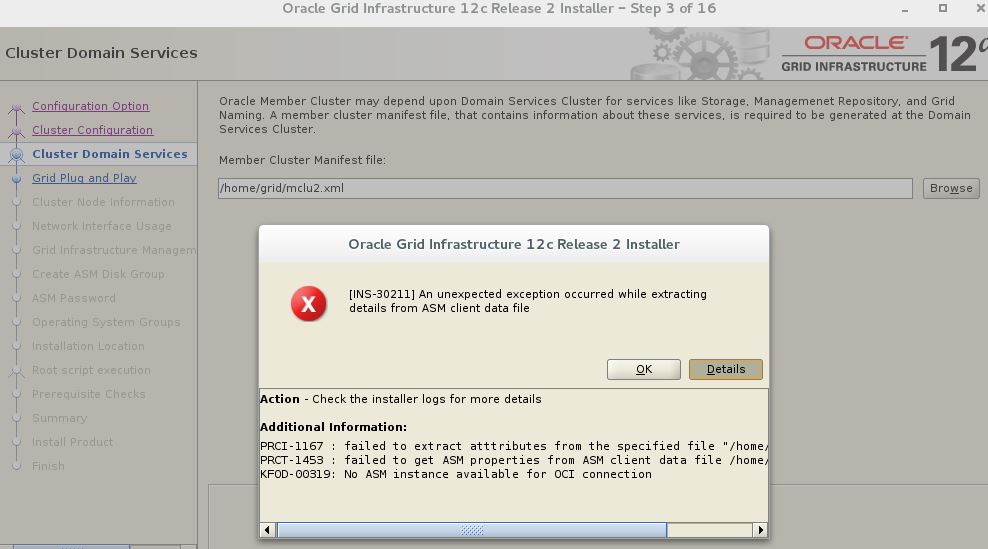
What to do first ?
Note 80 % of Clusterware startup problems are related to:
- Disk Space Problems
- Network Connectivity Problem with following system Calls are failing
- bind()
-
bind() specifies the address & port on the local side of the connection. Check for local IP changes including changes for Netmask, ...
- connect()
-
connect() specifies the address & port on the remote side of the connection. Check for remote IP changes including changes for Netmask, Firewall issues, ...
- gethostbyname()
-
Check your Nameserver connectivity and configuration
- File Protection Problems
This translates to some very important task before starting Clusterware Debugging :
-
- Check your disk space using: # df
- Check whether your are running a firewall: # service iptables status ( <— this command is very important and you should disable iptables asap if enabled )
- Check whether avahi daemon is running : # service avahi-daemon status
- Reboot your system to Cleanup special sockets file in: /var/tmp/.oracle
- Verify Network Connectivity ( ping, nslookup ) and don’t forget to ask your Network Admin for any changes done in last couple of days
- Check your ASM disks with kfed for a a valid ASM diskheader
[grid@ractw21 ~]$ kfed read /dev/sdb1 | egrep 'name|size|type'
kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD
kfdhdb.dskname: DATA3 ; 0x028: length=5
kfdhdb.grpname: DATA ; 0x048: length=4
kfdhdb.fgname: DATA3 ; 0x068: length=5
kfdhdb.secsize: 512 ; 0x0b8: 0x0200
kfdhdb.blksize: 4096 ; 0x0ba: 0x1000
kfdhdb.ausize: 4194304 ; 0x0bc: 0x00400000
kfdhdb.dsksize: 5119 ; 0x0c4: 0x000013ff
[grid@ractw21 ~]$ kfed read /dev/sdc1 | egrep 'name|size|type'
kfbh.type: 1 ; 0x002: KFBTYP_DISKHEAD
...
- If you need to manage multiple RAC clusters follow the Link below and dive into DTRACE more in detail:
Verify your system with cluvfy
1) If possible try to restart your failing node
If not - stop and restart at least your CRS stack
# crsctl stop crs -f
# crsclt start crs
2) If the problem persist collect following data
---> Working node
# olsnodes -n -i -s -t
# oifcfg getif
---> Failing node
# crsctl check crs
# crsctl check css
# crsctl check evm
# crsctl stat res -t -init
---> Run on all nodes and compare the results ( CI device name ,MTU and netmask should be identical )
# ifconfig -a
# df
# nestat -rn
Check that avahi is disabled and no Firewall is configured ( very important !! )
# service iptables status ( Linux specific command )
# service avahi status ( Linux specific command )
# nslookup grac41 ( use any all or your cluster nodes like grac41, grac42, grac43 )
Locate the cluster interconnect and ping the remote nodes
# oifcfg getif
eth3 192.168.3.0 global cluster_interconnect
[root@grac41 Desktop]# ifconfig | egrep 'eth3|192.168.3'
eth3 Link encap:Ethernet HWaddr 08:00:27:09:F0:99
inet addr:192.168.3.101 Bcast:192.168.3.255 Mask:255.255.255.0
--> Here we know eth3 is our cluster interconnect device with local address 192.168.3.101
[root@grac41 Desktop]# ping -I 192.168.3.101 192.168.3.102
[root@grac41 Desktop]# ping -I 192.168.3.101 192.168.3.103
Login as Grid-User and check the group permissions (compare results with a working node )
[grid@grac41 ~]$ id
3) Check your voting disks/OCR setup
On a working Node:
[root@grac41 Desktop]# ocrcheck
...
Device/File Name : +OCR
Locate the related disks
[grid@grac41 ~]$ asmcmd lsdsk -k
Total_MB Free_MB OS_MB Name Failgroup Failgroup_Type Library Label UDID Product Redund Path
2047 1695 2047 OCR_0000 OCR_0000 REGULAR System UNKNOWN /dev/asm_ocr_2G_disk1
2047 1697 2047 OCR_0001 OCR_0001 REGULAR System UNKNOWN /dev/asm_ocr_2G_disk2
2047 1697 2047 OCR_0002 OCR_0002 REGULAR System UNKNOWN /dev/asm_ocr_2G_disk3
On the failed node use kfed to read the disk header ( for all disks : asm_ocr_2G_disk1, asm_ocr_2G_disk2, asm_ocr_2G_disk3 )
[grid@grac41 ~]$ kfed read /dev/asm_ocr_2G_disk1 | grep name
kfdhdb.dskname: OCR_0000 ; 0x028: length=8
kfdhdb.grpname: OCR ; 0x048: length=3
kfdhdb.fgname: OCR_0000 ; 0x068: length=8
kfdhdb.capname: ; 0x088: length=0
4) Verify your cluster setup by runnig cluvfy
Download the 12.1 cluvfy from
http://www.oracle.com/technetwork/database/options/clustering/downloads/index.html and run
and extract the zip file and run as grid user:
Verify CRS installation ( if possible from a working node )
[grid@grac41 cluvf12]$ ./bin/cluvfy stage -post crsinst -n grac41,grac42 -verbose
Verify file protections ( run this on all nodes - verifies more than 1100 files )
[grid@grac41 cluvf12]$ ./bin/cluvfy comp software
..
1178 files verified
Software check failed
Overview
-
-
- Version tested GRID version 11.2.0.4.2 / OEL 6.5
- Before running any command from this article please backup OLR and OCR and your CW software !
It’s your responsibilty to have a valid backup !
Running any CW process as a wrong user can corrupt OLR,OCR and change protection for tracefiles and IPC sockets.
Must Read : Top 5 Grid Infrastructure Startup Issues (Doc ID 1368382.1)
-
-
- Issue #1: CRS-4639: Could not contact Oracle High Availability Services, ohasd.bin not running or ohasd.bin is running but no init.ohasd or other processes
- Issue #2: CRS-4530: Communications failure contacting Cluster Synchronization Services daemon, ocssd.bin is not running
- Issue #3: CRS-4535: Cannot communicate with Cluster Ready Services, crsd.bin is not running
- Issue #4: Agent or mdnsd.bin, gpnpd.bin, gipcd.bin not running
- Issue #5: ASM instance does not start, ora.asm is OFFLINE
How can I avoid CW troubleshooting by reading GB of traces – ( step 2 ) ?
Note more than 50 percents of CW startup problems can be avoided be checking the follwing
1. Check Network connectivity with ping, traceroute, nslookup
==> For further details see GENERIC Networking chapter
2. Check CW executable file protections ( compare with a working node )
$ ls -l $ORACLE_HOME/bin/gpnpd*
-rwxr-xr-x. 1 grid oinstall 8555 May 20 10:03 /u01/app/11204/grid/bin/gpnpd
-rwxr-xr-x. 1 grid oinstall 368780 Mar 19 17:07 /u01/app/11204/grid/bin/gpnpd.bin
3. Check CW log file and pid protections and ( compare with a working node )
$ ls -l ./grac41/gpnpd/grac41.pid
-rw-r--r--. 1 grid oinstall 6 May 22 11:46 ./grac41/gpnpd/grac41.pid
$ ls -l ./grac41/gpnpd/grac41.pid
-rw-r--r--. 1 grid oinstall 6 May 22 11:46 ./grac41/gpnpd/grac41.pid
4. Check IPC sockets protections( /var/tmp/.oracle )
$ ls -l /var/tmp/.oracle/sgrac41DBG_GPNPD
srwxrwxrwx. 1 grid oinstall 0 May 22 11:46 /var/tmp/.oracle/sgrac41DBG_GPNPD
==> For further details see GENERIC File Protection chapter
Overview CW startup sequence
In a nutshell, the operating system starts ohasd, ohasd starts agents to start up daemons
- Daemons: gipcd, mdnsd, gpnpd, ctssd, ocssd, crsd, evmd asm ..
After all local daemons are up crsd start agents that start user resources (database, SCAN, listener etc).
Startup sequence (from 11gR2 Clusterware and Grid Home - What You Need to Know (Doc ID 1053147.1) )
Level 1: OHASD Spawns:
cssdagent - Agent responsible for spawning CSSD.
orarootagent - Agent responsible for managing all root owned ohasd resources.
oraagent - Agent responsible for managing all oracle owned ohasd resources.
cssdmonitor - Monitors CSSD and node health (along wth the cssdagent).
Level 2b: OHASD rootagent spawns:
CRSD - Primary daemon responsible for managing cluster resources.
( CTSSD, ACFS , MDNSD, GIPCD, GPNPD, EVMD, ASM resources must be ONLINE )
CTSSD - Cluster Time Synchronization Services Daemon
Diskmon -
ACFS - ASM Cluster File System Drivers
Level 2a: OHASD oraagent spawns:
MDNSD - Used for DNS lookup
GIPCD - Used for inter-process and inter-node communication
GPNPD - Grid Plug & Play Profile Daemon
EVMD - Event Monitor Daemon
ASM - Resource for monitoring ASM instances
Level 3: CRSD spawns:
orarootagent - Agent responsible for managing all root owned crsd resources.
oraagent - Agent responsible for managing all oracle owned crsd resources.
Level 4: CRSD rootagent spawns:
Network resource - To monitor the public network
SCAN VIP(s) - Single Client Access Name Virtual IPs
Node VIPs - One per node
ACFS Registery - For mounting ASM Cluster File System
GNS VIP (optional) - VIP for GNS
Level 4: CRSD oraagent spawns:
ASM Resouce - ASM Instance(s) resource
Diskgroup - Used for managing/monitoring ASM diskgroups.
DB Resource - Used for monitoring and managing the DB and instances
SCAN Listener - Listener for single client access name, listening on SCAN VIP
Listener - Node listener listening on the Node VIP
Services - Used for monitoring and managing services
ONS - Oracle Notification Service
eONS - Enhanced Oracle Notification Service
GSD - For 9i backward compatibility
GNS (optional) - Grid Naming Service - Performs name resolution
Stopping CRS after CW startup failures
During testing you may stop CRS very frequently.
As the OHASD stack may not fully up you need to run:
[root@grac41 gpnp]# crsctl stop crs -f
CRS-2791: Starting shutdown of Oracle High Availability Services-managed resources on 'grac41'
CRS-2673: Attempting to stop 'ora.crsd' on 'grac41'
CRS-4548: Unable to connect to CRSD
CRS-5022: Stop of resource "ora.crsd" failed: current state is "INTERMEDIATE"
CRS-2675: Stop of 'ora.crsd' on 'grac41' failed
CRS-2679: Attempting to clean 'ora.crsd' on 'grac41'
CRS-4548: Unable to connect to CRSD
CRS-5022: Stop of resource "ora.crsd" failed: current state is "INTERMEDIATE"
CRS-2678: 'ora.crsd' on 'grac41' has experienced an unrecoverable failure
CRS-0267: Human intervention required to resume its availability.
CRS-2799: Failed to shut down resource 'ora.crsd' on 'grac41'
CRS-2795: Shutdown of Oracle High Availability Services-managed resources on 'grac41' has failed
CRS-4687: Shutdown command has completed with errors.
CRS-4000: Command Stop failed, or completed with errors.
If this hangs you may need to kill CW processes at OS level
[root@grac41 gpnp]# ps -elf | egrep "PID|d.bin|ohas|oraagent|orarootagent|cssdagent|cssdmonitor" | grep -v grep
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 5812 1 0 80 0 - 2847 pipe_w 07:20 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run
4 S root 19164 5812 24 80 0 - 176663 futex_ 09:52 ? 00:00:04 /u01/app/11204/grid/bin/ohasd.bin restart
4 S root 19204 1 1 80 0 - 171327 futex_ 09:52 ? 00:00:00 /u01/app/11204/grid/bin/orarootagent.bin
4 S root 19207 1 0 -40 - - 159900 futex_ 09:52 ? 00:00:00 /u01/app/11204/grid/bin/cssdagent
4 S root 19209 1 0 -40 - - 160927 futex_ 09:52 ? 00:00:00 /u01/app/11204/grid/bin/cssdmonitor
4 S grid 19283 1 1 80 0 - 167890 futex_ 09:52 ? 00:00:00 /u01/app/11204/grid/bin/oraagent.bin
0 S grid 19308 1 0 80 0 - 74289 poll_s 09:52 ? 00:00:00 /u01/app/11204/grid/bin/mdnsd.bin
==> Kill remaining CW processes
[root@grac41 gpnp]# kill -9 19164 19204 19207 19209 19283 19308
Status of a working OHAS stack
-
-
- Note ora.discmon resource become only ONLINE in EXADATA configurations
[root@grac41 Desktop]# crsctl check crs
CRS-4638: Oracle High Availability Services is online
CRS-4537: Cluster Ready Services is online
CRS-4529: Cluster Synchronization Services is online
CRS-4533: Event Manager is online
[root@grac41 Desktop]# crsi
NAME TARGET STATE SERVER STATE_DETAILS
------------------------- ---------- ---------- ------------ ------------------
ora.asm ONLINE ONLINE grac41 Started
ora.cluster_interconnect.haip ONLINE ONLINE grac41
ora.crf ONLINE ONLINE grac41
ora.crsd ONLINE ONLINE grac41
ora.cssd ONLINE ONLINE grac41
ora.cssdmonitor ONLINE ONLINE grac41
ora.ctssd ONLINE ONLINE grac41 OBSERVER
ora.diskmon OFFLINE OFFLINE
ora.drivers.acfs ONLINE ONLINE grac41
ora.evmd ONLINE ONLINE grac41
ora.gipcd ONLINE ONLINE grac41
ora.gpnpd ONLINE ONLINE grac41
ora.mdnsd ONLINE ONLINE grac41
Ohasd startup scritps on OEL 6
OHASD Script location
[root@grac41 init.d]# find /etc |grep S96
/etc/rc.d/rc5.d/S96ohasd
/etc/rc.d/rc3.d/S96ohasd
[root@grac41 init.d]# ls -l /etc/rc.d/rc5.d/S96ohasd
lrwxrwxrwx. 1 root root 17 May 4 10:57 /etc/rc.d/rc5.d/S96ohasd -> /etc/init.d/ohasd
[root@grac41 init.d]# ls -l /etc/rc.d/rc3.d/S96ohasd
lrwxrwxrwx. 1 root root 17 May 4 10:57 /etc/rc.d/rc3.d/S96ohasd -> /etc/init.d/ohasd
--> Run level 3 and 5 should start ohasd
Check status of init.ohasd process
[root@grac41 bin]# more /etc/init/oracle-ohasd.conf
# Copyright (c) 2001, 2011, Oracle and/or its affiliates. All rights reserved.
#
# Oracle OHASD startup
start on runlevel [35]
stop on runlevel [!35]
respawn
exec /etc/init.d/init.ohasd run >/dev/null 2>&1 </dev/null
List current PID
[root@grac41 Desktop]# initctl list | grep oracle-ohasd
oracle-ohasd start/running, process 27558
Check OS processes
[root@grac41 Desktop]# ps -elf | egrep "PID|d.bin|ohas|oraagent|orarootagent|cssdagent|cssdmonitor" | grep -v grep
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 27558 1 0 80 0 - 2878 wait 07:01 ? 00:00:02 /bin/sh /etc/init.d/init.ohasd run
Useful OS and CW commands, GREP commands , OS logfile location and Clusterware logfile location details
1 : Clusterware logfile structure
CW Alert.log alert<hostname>.log ( most important one !! )
OHASD ohsad.log
CSSD ocssd.log
EVMD evmd.log
CRSD crsd.log
MDSND mdnsd.log
GIPCD gipcd.log
GPNPD gpnpd.log
Agent directories
agent/ohasd
agent/ohasd/oraagent_grid
agent/ohasd/oracssdagent_root
agent/ohasd/oracssdmonitor_root
agent/ohasd/orarootagent_root
2 : OS System logs
HPUX /var/adm/syslog/syslog.log
AIX /bin/errpt–a
Linux /var/log/messages
Windows Refer .TXT log files under Application/System log using Windows Event Viewer
Solaris /var/adm/messages
Linux Sample
# grep 'May 20' ./grac41/var/log/messages > SYSLOG
--> Check SYSLOG for relvant errors
An typical CW error could look like:
# cat /var/log/messages
May 13 13:48:27 grac41 OHASD[22203]: OHASD exiting; Directory /u01/app/11204/grid/log/grac41/ohasd not found
3 : Usefull Commands for a quick check of clusterware status
It may be usefull to run all commands below just to get an idea what is working and what is not working
3.1 : OS commands ( assume we have CW startup problems on grac41 )
# ping grac41
# route -n
# /bin/netstat -in
# /sbin/ifconfig -a
# /bin/ping -s <MTU> -c 2 -I source_IP nodename
# /bin/traceroute -s source_IP -r -F nodename-priv <MTU-28>
# /usr/bin/nslookup grac41
3.2 : Clusterware commands to debug startup problems
Check Clusterware status
# crsctl check crs
# crsctl check css
# crsctl check evm
# crsctl stat res -t -init
If OHASD stack is completly up and running you can check your cluster resources with
# crsctl stat res -t
3.3 : Checking OLR to debug startup problems
# ocrcheck -local
# ocrcheck -local -config
3.4 : Checking OCR/Votedisks to debug startup problems
$ crsctl query css votedisk
Next 2 commands will only work when startup problems are fixed
$ ocrcheck
$ ocrcheck -config
3.5 : Checking GPnP to debug startup problems
# $GRID_HOME/bin/gpnptool get
For futher debugging
# $GRID_HOME/bin/gpnptool lfind
# $GRID_HOME/bin/gpnptool getpval -asm_spf -p=/u01/app/11204/grid/gpnp/profiles/peer/profile.xml
# $GRID_HOME/bin/gpnptool check -p=/u01/app/11204/grid/gpnp/profiles/peer/profile.xml
# $GRID_HOME/bin/gpnptool verify -p=/u01/app/11204/grid/gpnp/profiles/peer/profile.xml -w="/u01/app/11204/grid/gpnp/grac41/wallets/peer" -wu=peer
3.6 : Cluvfy commands to debug startup problems
Network problems:
$ cluvfy comp nodereach -n grac41 -vebose
Identify your interfaces used for public and private usage and check related networks
$ cluvfy comp nodecon -n grac41,grac42 -i eth1 -verbose ( public Interface )
$ cluvfy comp nodecon -n grac41,grac42 -i eth2 -verbose ( private Interface )
$ cluvfy comp nodecon -n grac41 -verbose
Testing multicast communication for multicast group "230.0.1.0" .
$ cluvfy stage -post hwos -n grac42
Cluvfy commands to verify ASM DG and Voting disk location
Note: Run cluvfy from a working Node ( grac42 ) to get more details
[grid@grac42 ~]$ cluvfy comp vdisk -n grac41
ERROR: PRVF-5157 : Could not verify ASM group "OCR" for Voting Disk location "/dev/asmdisk1_udev_sdh1"
--> From the error code we know ASM disk group + Voting Disk location
$ cluvfy comp olr -verbose
$ cluvfy comp software -verbose
$ cluvfy comp ocr -n grac42,grac41
$ cluvfy comp sys -n grac41 -p crs -verbose
Comp healthcheck is quite helpfull to get an overview but as OHASD is not running most of the
errors are related to the CW startup problem.
$ cluvfy comp healthcheck -collect cluster -html
$ firefox cvucheckreport_523201416347.html
4 : Useful grep Commands
GPnP profile is not accessible - gpnpd needs to be fully up to serve profile
$ fn_egrep.sh "Cannot get GPnP profile|Error put-profile CALL"
TraceFileName: ./grac41/agent/ohasd/orarootagent_root/orarootagent_root.log
2014-05-20 10:26:44.532: [ default][1199552256]Cannot get GPnP profile. Error CLSGPNP_NO_DAEMON (GPNPD daemon is not running).
Cannot get GPnP profile
2014-04-21 15:27:06.838: [ GPNP][132114176]clsgpnp_profileCallUrlInt: [at clsgpnp.c:2243] Result: (13) CLSGPNP_NO_DAEMON.
Error put-profile CALL to remote "tcp://grac41:56376" disco "mdns:service:gpnp._tcp.local.://grac41:56376/agent=gpnpd,cname=grac4,host=grac41,pid=4548/gpnpd h:grac41 c:grac4"
Network socket file doesn't have appropriate ownership or permission
# fn_egrep.sh "clsclisten: Permission denied"
[ COMMCRS][3534915328]clsclisten: Permission denied for (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_MDNSD))
Problems with Private Interconnect
$ fn.sh "2014-06-03" | egrep 'but no network HB|TraceFileName'
Search String: no network HB
TraceFileName: ./cssd/ocssd.log
2014-06-02 12:51:52.564: [ CSSD][2682775296]clssnmvDHBValidateNcopy: node 3, grac43, has a disk HB, but no network HB , ..
or
$ fn_egrep.sh "failed to resolve|gipcretFail|gipcretConnectionRefused" | egrep 'TraceFile|2014-05-20 11:0'
TraceFileName: ./grac41/crsd/crsd.log and ./grac41/evmd/evmd.log may report
2014-05-20 11:04:02.563: [GIPCXCPT][154781440] gipchaInternalResolve: failed to resolve ret gipcretKeyNotFound (36), host 'grac41', port 'ffac-854b-c525-6f9c', hctx 0x2ed3940 [0000000000000010] { gipchaContext : host 'grac41', name 'd541-9a1e-7807-8f4a', luid 'f733b93a-00000000', numNode 0, numInf 1, usrFlags 0x0, flags 0x5 }, ret gipcretKeyNotFound (36)
2014-05-20 11:04:02.563: [GIPCHGEN][154781440] gipchaResolveF [gipcmodGipcResolve : gipcmodGipc.c : 806]: EXCEPTION[ ret gipcretKeyNotFound (36) ] failed to resolve ctx 0x2ed3940 [0000000000000010] { gipchaContext : host 'grac41', name 'd541-9a1e-7807-8f4a', luid 'f733b93a-00000000', numNode 0, numInf 1, usrFlags 0x0, flags 0x5 }, host 'grac41', port 'ffac-854b-c525-6f9c', flags 0x0
Is there a valid CI network device ?
# fn_egrep.sh "NETDATA" | egrep 'TraceFile|2014-06-03'
TraceFileName: ./gipcd/gipcd.log
2014-06-03 07:48:45.401: [ CLSINET][3977414400] Returning NETDATA: 1 interfaces <-- ok
2014-06-03 07:52:51.589: [ CLSINET][1140848384] Returning NETDATA: 0 interfaces <-- problems !
Are Voting Disks acessible ?
$ fn_egrep.sh "Successful discovery"
TraceFileName: ./grac41/cssd/ocssd.log
2014-05-22 13:41:38.776: [ CSSD][1839290112]clssnmvDiskVerify: Successful discovery of 0 disks
Generic trobleshooting hints : How to review CW trace files
1 : Limit trace files size and file count by using TFA command: tfactl diagcollect
Note only single node collection is neccessary for CW startup problem - here node grac41 has CW startup problems
# tfactl diagcollect -node grac41 -from "May/20/2014 06:00:00" -to "May/20/2014 15:00:00"
--> Scanning files from May/20/2014 06:00:00 to May/20/2014 15:00:00
...
Logs are collected to:
/u01/app/grid/tfa/repository/collection_Wed_May_21_09_19_10_CEST_2014_node_grac41/grac41.tfa_Wed_May_21_09_19_10_CEST_2014.zip
Extract zip file and scan for various Clusterware errors
# mkdir /u01/TFA
# cd /u01/TFA
# unzip /u01/app/grid/tfa/repository/collection_Wed_May_21_09_19_10_CEST_2014_node_grac41/grac41.tfa_Wed_May_21_09_19_10_CEST_2014.zip
Locate important files in our unzipped TFA repository
# pwd
/u01/TFA/
# find . -name "alert*"
./grac41/u01/app/11204/grid/log/grac41/alertgrac41.log
./grac41/asm/+asm/+ASM1/trace/alert_+ASM1.log
./grac41/rdbms/grac4/grac41/trace/alert_grac41.log
# find . -name "mess*"
./grac41/var/log/messages
./grac41/var/log/messages-20140504
2 : Review Clusterware alert.log errors
# get_ca.sh alertgrac41.log 2014-05-23
-> File searched: alertgrac41.log
-> Start search timestamp : 2014-05-23
-> End search timestamp :
Begin: CNT 0 - TS --
2014-05-23 15:29:31.297: [mdnsd(16387)]CRS-5602:mDNS service stopping by request.
2014-05-23 15:29:34.211: [gpnpd(16398)]CRS-2329:GPNPD on node grac41 shutdown.
2014-05-23 15:29:45.785: [ohasd(2736)]CRS-2112:The OLR service started on node grac41.
2014-05-23 15:29:45.845: [ohasd(2736)]CRS-1301:Oracle High Availability Service started on node grac41.
2014-05-23 15:29:45.861: [ohasd(2736)]CRS-8017:location: /etc/oracle/lastgasp has 2 reboot advisory log files, 0 were announced and 0 errors occurred
2014-05-23 15:29:49.999: [/u01/app/11204/grid/bin/orarootagent.bin(2798)]CRS-2302:Cannot get GPnP profile.
Error CLSGPNP_NO_DAEMON (GPNPD daemon is not running).
2014-05-23 15:29:55.075: [ohasd(2736)]CRS-2302:Cannot get GPnP profile. Error CLSGPNP_NO_DAEMON (GPNPD daemon is not running).
2014-05-23 15:29:55.081: [gpnpd(2934)]CRS-2328:GPNPD started on node grac41.
2014-05-23 15:29:57.576: [cssd(3040)]CRS-1713:CSSD daemon is started in clustered mode
2014-05-23 15:29:59.331: [ohasd(2736)]CRS-2767:Resource state recovery not attempted for 'ora.diskmon' as its target state is OFFLINE
2014-05-23 15:29:59.331: [ohasd(2736)]CRS-2769:Unable to failover resource 'ora.diskmon'.
2014-05-23 15:30:01.905: [cssd(3040)]CRS-1714:Unable to discover any voting files, retrying discovery in 15 seconds;
Details at (:CSSNM00070:) in /u01/app/11204/grid/log/grac41/cssd/ocssd.log
2014-05-23 15:30:16.945: [cssd(3040)]CRS-1714:Unable to discover any voting files, retrying discovery in 15 seconds;
Details at (:CSSNM00070:) in /u01/app/11204/grid/log/grac41/cssd/ocssd.log
--> Script get_ca.sh adds a timestamp and reduces output and only dumps errors for certain day
In the above sample we can easily pin-point the problem to a voting disks issue
If you cant find a obvious reason you still need to review your clusterware alert.log
3 : Review Clusterware logfiles for errors and resources failing or not starting up
$ fn.sh 2014-05-25 | egrep 'TraceFileName|CRS-|ORA-|TNS-|LFI-|KFNDG-|KFED-|KFOD-|CLSDNSSD-|CLSGN-|CLSMDNS-|CLS.-
|NDFN-|EVM-|GIPC-|PRK.-|PRV.-|PRC.-|PRIF-|SCLS-|PROC-|PROCL-|PROT-|PROTL-'
TraceFileName: ./crsd/crsd.log
2014-05-25 11:29:04.968: [ CRSPE][1872742144]{1:62631:2} CRS-2672: Attempting to start 'ora.SSD.dg' on 'grac41'
2014-05-25 11:29:04.999: [ CRSPE][1872742144]{1:62631:2} CRS-2672: Attempting to start 'ora.DATA.dg' on 'grac41'
2014-05-25 11:29:05.063: [ CRSPE][1872742144]{1:62631:2} CRS-2672: Attempting to start 'ora.FRA.dg' on 'grac41
....
If a certain resource like ora.net1.network doesn't start - grep for details using resource name
[grid@grac42 grac42]$ fn.sh "ora.net1.network" | egrep '2014-05-31 11|TraceFileName'
TraceFileName: ./agent/crsd/orarootagent_root/orarootagent_root.log
2014-05-31 11:58:27.899: [ AGFW][1829066496]{2:12808:5} Agent received the message: RESOURCE_START[ora.net1.network grac42 1] ID 4098:403
2014-05-31 11:58:27.899: [ AGFW][1829066496]{2:12808:5} Preparing START command for: ora.net1.network grac42 1
2014-05-31 11:58:27.899: [ AGFW][1829066496]{2:12808:5} ora.net1.network grac42 1 state changed from: OFFLINE to: STARTING
2014-05-31 11:58:27.917: [ AGFW][1826965248]{2:12808:5} Command: start for resource: ora.net1.network grac42 1 completed with status: SUCCESS
2014-05-31 11:58:27.919: [ AGFW][1829066496]{2:12808:5} Agent sending reply for: RESOURCE_START[ora.net1.network grac42 1] ID 4098:403
2014-05-31 11:58:27.969: [ AGFW][1829066496]{2:12808:5} ora.net1.network grac42 1 state changed from: STARTING to: UNKNOWN
4 : Review ASM alert.log
5 : Track generation of new Tints and follow these Tints
$ fn.sh 2014-05-25 | egrep 'TraceFileName|Generating new Tint'
TraceFileName: ./agent/ohasd/orarootagent_root/orarootagent_root.log
2014-05-25 13:52:07.862: [ AGFW][2550134528]{0:11:3} Generating new Tint for unplanned state change. Original Tint: {0:0:2}
2014-05-25 13:52:36.126: [ AGFW][2550134528]{0:11:6} Generating new Tint for unplanned state change. Original Tint: {0:0:2}
[grid@grac41 grac41]$ fn.sh "{0:11:3}" | more
Search String: {0:11:3}
TraceFileName: ./alertgrac41.log
[/u01/app/11204/grid/bin/cssdmonitor(1833)]CRS-5822:Agent '/u01/app/11204/grid/bin/cssdmonitor_root' disconnected from server. Details at (:CRSAGF00117:) {0:11:3}
in /u01/app/11204/grid/log/grac41/agent/ohasd/oracssdmonitor_root/oracssdmonitor_root.log.
--------------------------------------------------------------------
TraceFileName: ./agent/ohasd/oracssdmonitor_root/oracssdmonitor_root.log
2014-05-19 14:34:03.312: [ AGENT][3481253632]{0:11:3} {0:11:3} Created alert : (:CRSAGF00117:) :
Disconnected from server, Agent is shutting down.
2014-05-19 14:34:03.312: [ USRTHRD][3481253632]{0:11:3} clsncssd_exit: CSSD Agent was asked to exit with exit code 2
2014-05-19 14:34:03.312: [ USRTHRD][3481253632]{0:11:3} clsncssd_exit: No connection with CSS, exiting.
6 : Investigate GENERIC File Protection problems for Log File Location, Ownership and Permissions
==> For further details see GENERIC File Protection troubleshooting chapter
7 : Investigate GENERIC Networking problems
==> For further details see GENERIC Networking troubleshooting chapter
8 : Check logs for a certain resource for a certain time ( in this sample ora.gpnpd resource was used)
[root@grac41 grac41]# fn.sh "ora.gpnpd" | egrep "TraceFileName|2014-05-22 07" | more
TraceFileName: ./agent/ohasd/oraagent_grid/oraagent_grid.log
2014-05-22 07:18:27.281: [ora.gpnpd][3696797440]{0:0:2} [check] clsdmc_respget return: status=0, ecode=0
2014-05-22 07:18:57.291: [ora.gpnpd][3698898688]{0:0:2} [check] clsdmc_respget return: status=0, ecode=0
2014-05-22 07:19:27.290: [ora.gpnpd][3698898688]{0:0:2} [check] clsdmc_respget return: status=0, ecode=0
9 : Check related trace depending on startup dependencies
GPndp daemon has the following dependencies: OHASD (root) starts --> OHASD ORAgent (grid) starts --> GPnP (grid)
Following tracefile needs to reviewed first for add. info
./grac41/u01/app/11204/grid/log/grac41/gpnpd/gpnpd.log ( see above )
./grac41/u01/app/11204/grid/log/grac41/ohasd/ohasd.log
./grac41/u01/app/11204/grid/log/grac41/agent/ohasd/oraagent_grid/oraagent_grid.log
10 : Check for tracefiles updated very frequently ( this helps to identify looping processes )
# date ; find . -type f -printf "%CY-%Cm-%Cd %CH:%CM:%CS %h/%f\n" | sort -n | tail -5
Thu May 22 07:52:45 CEST 2014
2014-05-22 07:52:12.1781722420 ./grac41/alertgrac41.log
2014-05-22 07:52:44.8401175210 ./grac41/agent/ohasd/oraagent_grid/oraagent_grid.log
2014-05-22 07:52:45.2701299670 ./grac41/client/crsctl_grid.log
2014-05-22 07:52:45.2901305450 ./grac41/ohasd/ohasd.log
2014-05-22 07:52:45.3221314710 ./grac41/client/olsnodes.log
# date ; find . -type f -printf "%CY-%Cm-%Cd %CH:%CM:%CS %h/%f\n" | sort -n | tail -5
Thu May 22 07:52:48 CEST 2014
2014-05-22 07:52:12.1781722420 ./grac41/alertgrac41.log
2014-05-22 07:52:47.3701907460 ./grac41/client/crsctl_grid.log
2014-05-22 07:52:47.3901913240 ./grac41/ohasd/ohasd.log
2014-05-22 07:52:47.4241923080 ./grac41/client/olsnodes.log
2014-05-22 07:52:48.3812200070 ./grac41/agent/ohasd/oraagent_grid/oraagent_grid.log
Check these trace files with tail -f
# tail -f ./grac41/agent/ohasd/oraagent_grid/oraagent_grid.log
[ clsdmc][1975785216]Fail to connect (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_GPNPD)) with status 9
2014-05-22 07:56:11.198: [ora.gpnpd][1975785216]{0:0:2} [start] Error = error 9 encountered when connecting to GPNPD
2014-05-22 07:56:12.199: [ora.gpnpd][1975785216]{0:0:2} [start] without returnbuf
2014-05-22 07:56:12.382: [ COMMCRS][1966565120]clsc_connect: (0x7fd9500cc070) no listener at (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_GPNPD))
[ clsdmc][1975785216]Fail to connect (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_GPNPD)) with status 9
2014-05-22 07:56:12.382: [ora.gpnpd][1975785216]{0:0:2} [start] Error = error 9 encountered when connecting to GPNPD
2014-05-22 07:56:13.382: [ora.gpnpd][1975785216]{0:0:2} [start] without returnbuf
2014-05-22 07:56:13.553: [ COMMCRS][1966565120]clsc_connect: (0x7fd9500cc070) no listener at (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_GPNPD))
--> Problem is we can't connect to the GPNPD listener
# ps -elf | egrep "PID|d.bin|ohas" | grep -v grep
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 1560 1 0 -40 - - 160927 futex_ 07:56 ? 00:00:00 /u01/app/11204/grid/bin/cssdmonitor
4 S root 4494 1 0 80 0 - 2846 pipe_w May21 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run
4 S root 30441 1 23 80 0 - 176982 futex_ 07:49 ? 00:02:04 /u01/app/11204/grid/bin/ohasd.bin reboot
4 S grid 30612 1 0 80 0 - 167327 futex_ 07:50 ? 00:00:05 /u01/app/11204/grid/bin/oraagent.bin
0 S grid 30623 1 0 80 0 - 74289 poll_s 07:50 ? 00:00:00 /u01/app/11204/grid/bin/mdnsd.bin
--> Indeed gpnpd is not running . Investiage this further by debugging CW with strace
11 : If still no root cause was found try to grep all message for that period and review the output carefully
# fn.sh "2014-05-20 07:2" | more
Search String: 2014-05-20 07:2
...
--------------------------------------------------------------------
TraceFileName: ./grac41/u01/app/11204/grid/log/grac41/agent/ohasd/oraagent_grid/oraagent_grid.l01
2014-05-20 07:23:04.338: [ AGFW][374716160]{0:0:2} Agent received the message: AGENT_HB[Engine] ID 12293:1236
....
--------------------------------------------------------------------
TraceFileName: ./grac41/u01/app/11204/grid/log/grac41/gpnpd/gpnpd.log
2014-05-20 07:23:13.385: [ default][4133218080]
2014-05-20 07:23:13.385: [ default][4133218080]gpnpd START pid=16641 Oracle Grid Plug-and-Play Daemon
GENERIC File Protection problems for Log File Location, Ownership and Permissions
-
-
- Resource reports status STARTING for a long time before failing with CRS errors
- After some time resource becomes OFFLINE
Debug startup problems for GPnP daemon
Case #1 : Check that GPnP daemon can write to trace file location and new timestamps are written
Following directory/files needs to have proper protections :
Trace directory : ./log/grac41/gpnpd
STDOUT log file : ./log/grac41/gpnpd/gpnpdOUT.log
Error log file : ./log/grac41/gpnpd/gpnpd.log
If gpnpdOUT.log and gpnpd.log are not updated when starting GPnP daemon you need to review your file protections
Sample for GPnP resource:
# ls -ld ./grac41/u01/app/11204/grid/log/grac41/gpnpd
drwxr-xr-x. 2 root root 4096 May 21 09:52 ./grac41/u01/app/11204/grid/log/grac41/gpnpd
# ls -l ./grac41/u01/app/11204/grid/log/grac41/gpnpd
-rw-r--r--. 1 root root 420013 May 21 09:35 gpnpd.log
-rw-r--r--. 1 root root 26567 May 21 09:31 gpnpdOUT.log
==> Here we can see that trace files are owned by root which is wrong !
After changing directory and tracefils with chown grid:oinstall ... traces where sucessfully written
If unsure about protection verify this with a cluster node where CRS is up and running
# ls -ld /u01/app/11204/grid/log/grac41/gpnpd
drwxr-x---. 2 grid oinstall 4096 May 20 13:53 /u01/app/11204/grid/log/grac41/gpnpd
# ls -l /u01/app/11204/grid/log/grac41/gpnpd
-rw-r--r--. 1 grid oinstall 122217 May 19 13:35 gpnpd_1.log
-rw-r--r--. 1 grid oinstall 1747836 May 20 12:32 gpnpd.log
-rw-r--r--. 1 grid oinstall 26567 May 20 12:31 gpnpdOUT.log
Case #2 : Check that IPC sockets have proper protection (this info is not available via tfa collector )
( verify this with a node where CRS is up and running )
# ls -l /var/tmp/.oracle | grep -i gpnp
srwxrwxrwx. 1 grid oinstall 0 May 20 12:31 ora_gipc_GPNPD_grac41
-rw-r--r--. 1 grid oinstall 0 May 20 10:11 ora_gipc_GPNPD_grac41_lock
srwxrwxrwx. 1 grid oinstall 0 May 20 12:31 sgrac41DBG_GPNPD
==> Again check this against a working cluster node
You may consider to compare all IPC socket info available in /var/tmp/.oracle
Same sort of debugging can be used for other processes like MDNSD daemon
MDNSD process can't listen to IPC socket grac41DBG_MDNSD socket and terminates
Grep command:
$ fn_egrep.sh "clsclisten: Permission denied"
TraceFileName: ./grac41/mdnsd/mdnsd.log
2014-05-19 08:08:53.097: [ COMMCRS][2179102464]clsclisten: Permission denied for (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_MDNSD))
2014-05-19 08:10:58.177: [ COMMCRS][3534915328]clsclisten: Permission denied for (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_MDNSD))
Trace file extract: ./grac41/mdnsd/mdnsd.log
2014-05-19 08:08:53.087: [ default][2187654912]mdnsd START pid=11855
2014-05-19 08:08:53.097: [ COMMCRS][2179102464]clsclisten: Permission denied for (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_MDNSD))
--> Permissiong problems for MDNSD resource
2014-05-19 08:08:53.097: [ clsdmt][2181203712]Fail to listen to (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_MDNSD))
2014-05-19 08:08:53.097: [ clsdmt][2181203712]Terminating process
2014-05-19 08:08:53.097: [ MDNS][2181203712] clsdm requested mdnsd exit
2014-05-19 08:08:53.097: [ MDNS][2181203712] mdnsd exit
2014-05-19 08:10:58.168: [ default][3543467776]
Case #3 : Check gpnpd.log for sucessful write of the related PID file
# egrep "PID for the Process|Creating PID|Writing PID" ./grac41/u01/app/11204/grid/log/grac41/gpnpd/gpnpd.log
2014-05-20 07:23:13.417: [ clsdmt][4121581312]PID for the Process [16641], connkey 10
2014-05-20 07:23:13.417: [ clsdmt][4121581312]Creating PID [16641] file for home /u01/app/11204/grid host grac41 bin gpnp to /u01/app/11204/grid/gpnp/init/
2014-05-20 07:23:13.417: [ clsdmt][4121581312]Writing PID [16641] to the file [/u01/app/11204/grid/gpnp/init/grac41.pid]
Case #4 : Check gpnpd.log file for fatal errors like PROCL-5 PROCL-26
# less ./grac41/u01/app/11204/grid/log/grac41/gpnpd/gpnpd.log
2014-05-20 07:23:14.377: [ GPNP][4133218080]clsgpnpd_openLocalProfile: [at clsgpnpd.c:3477] Got local profile from file cache provider (LCP-FS).
2014-05-20 07:23:14.380: [ GPNP][4133218080]clsgpnpd_openLocalProfile: [at clsgpnpd.c:3532] Got local profile from OLR cache provider (LCP-OLR).
2014-05-20 07:23:14.385: [ GPNP][4133218080]procr_open_key_ext: OLR api procr_open_key_ext failed for key SYSTEM.GPnP.profiles.peer.pending
2014-05-20 07:23:14.386: [ GPNP][4133218080]procr_open_key_ext: OLR current boot level : 7
2014-05-20 07:23:14.386: [ GPNP][4133218080]procr_open_key_ext: OLR error code : 5
2014-05-20 07:23:14.386: [ GPNP][4133218080]procr_open_key_ext: OLR error message : PROCL-5: User does not have permission to perform a local
registry operation on this key. Authentication error [User does not have permission to perform this operation] [0]
2014-05-20 07:23:14.386: [ GPNP][4133218080]clsgpnpco_ocr2profile: [at clsgpnpco.c:578] Result: (58) CLSGPNP_OCR_ERR. Failed to open requested OLR Profile.
2014-05-20 07:23:14.386: [ GPNP][4133218080]clsgpnpd_lOpen: [at clsgpnpd.c:1734] Listening on ipc://GPNPD_grac41
2014-05-20 07:23:14.386: [ GPNP][4133218080]clsgpnpd_lOpen: [at clsgpnpd.c:1743] GIPC gipcretFail (1) gipcListen listen failure on
2014-05-20 07:23:14.386: [ default][4133218080]GPNPD failed to start listening for GPnP peers.
2014-05-20 07:23:14.388: [ GPNP][4133218080]clsgpnpd_term: [at clsgpnpd.c:1344] STOP GPnPD terminating. Closing connections...
2014-05-20 07:23:14.400: [ default][4133218080]clsgpnpd_term STOP terminating.
GENERIC Networking troubleshooting chapter
-
-
- Private IP address is not directly used by clusterware
- If changing IP from 192.168.2.102 to 192.168.2.108 CW still comes up as network address 192.168.2.0 does not change
- If changing IP from 192.168.2.102 to 192.168.3.103 CW doesn’t come up as network address changed from 192.168.2.0 to 192.168.3.0 – Network address is used by GPnP profile.xml for private and public network
- Check crfmond/crfmond.trc trace file for private network errors ( usefull for CI errors )
- If you get any GIPC error message always think on a real network problems first
Case #1 : Nameserver not running/available
Reported error in evmd.log : [ OCRMSG][3360876320]GIPC error [29] msg [gipcretConnectionRefused
Reported Clusterware Error in CW alert.log: CRS-5011:Check of resource "+ASM" failed:
Testing scenario :
Stop nameserver and restart CRS
# crsctl start crs
CRS-4123: Oracle High Availability Services has been started.
Clusterware status
[root@grac41 gpnpd]# crsctl check crs
CRS-4638: Oracle High Availability Services is online
CRS-4535: Cannot communicate with Cluster Ready Services
CRS-4529: Cluster Synchronization Services is online
CRS-4534: Cannot communicate with Event Manager
--> CSS, HAS are ONLINE - EVM and CRS are OFFLINE
# ps -elf | egrep "PID|d.bin|ohas|oraagent|orarootagent|cssdagent|cssdmonitor" | grep -v grep
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 5396 1 0 80 0 - 2847 pipe_w 10:52 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run
4 S root 9526 1 3 80 0 - 178980 futex_ 14:47 ? 00:00:08 /u01/app/11204/grid/bin/ohasd.bin reboot
4 S grid 9705 1 0 80 0 - 174922 futex_ 14:47 ? 00:00:00 /u01/app/11204/grid/bin/oraagent.bin
0 S grid 9716 1 0 80 0 - 74289 poll_s 14:47 ? 00:00:00 /u01/app/11204/grid/bin/mdnsd.bin
0 S grid 9749 1 1 80 0 - 127375 hrtime 14:47 ? 00:00:02 /u01/app/11204/grid/bin/gpnpd.bin
0 S grid 9796 1 1 80 0 - 159711 hrtime 14:47 ? 00:00:04 /u01/app/11204/grid/bin/gipcd.bin
4 S root 9799 1 1 80 0 - 168656 futex_ 14:47 ? 00:00:03 /u01/app/11204/grid/bin/orarootagent.bin
4 S root 9812 1 3 -40 - - 160908 hrtime 14:47 ? 00:00:08 /u01/app/11204/grid/bin/osysmond.bin
4 S root 9823 1 0 -40 - - 162793 futex_ 14:47 ? 00:00:00 /u01/app/11204/grid/bin/cssdmonitor
4 S root 9842 1 0 -40 - - 162920 futex_ 14:47 ? 00:00:00 /u01/app/11204/grid/bin/cssdagent
4 S grid 9855 1 2 -40 - - 166594 futex_ 14:47 ? 00:00:04 /u01/app/11204/grid/bin/ocssd.bin
4 S root 10884 1 1 80 0 - 159388 futex_ 14:48 ? 00:00:02 /u01/app/11204/grid/bin/octssd.bin reboot
0 S grid 10904 1 0 80 0 - 75285 hrtime 14:48 ? 00:00:00 /u01/app/11204/grid/bin/evmd.bin
$ crsi
NAME TARGET STATE SERVER STATE_DETAILS
------------------------- ---------- ---------- ------------ ------------------
ora.asm ONLINE OFFLINE CLEANING
ora.cluster_interconnect.haip ONLINE ONLINE grac41
ora.crf ONLINE ONLINE grac41
ora.crsd ONLINE OFFLINE
ora.cssd ONLINE ONLINE grac41
ora.cssdmonitor ONLINE ONLINE grac41
ora.ctssd ONLINE ONLINE grac41 OBSERVER
ora.diskmon OFFLINE OFFLINE
ora.drivers.acfs ONLINE ONLINE grac41
ora.evmd ONLINE INTERMEDIATE grac41
ora.gipcd ONLINE ONLINE grac41
ora.gpnpd ONLINE ONLINE grac41
ora.mdnsd ONLINE ONLINE grac41
--> Event manager is in INTERMEDIATE state --> need to reivew EVMD logfile first
Detailed Tracefile report
Grep Syntax:
$ fn_egrep.sh "failed to resolve|gipcretFail" | egrep 'TraceFile|2014-05-20 11:0'
Failed case:
TraceFileName: ./grac41/crsd/crsd.log and ./grac41/evmd/evmd.log may report
2014-05-20 11:04:02.563: [GIPCXCPT][154781440] gipchaInternalResolve: failed to resolve ret gipcretKeyNotFound (36),
host 'grac41', port 'ffac-854b-c525-6f9c', hctx 0x2ed3940 [0000000000000010] { gipchaContext :
host 'grac41', name 'd541-9a1e-7807-8f4a', luid 'f733b93a-00000000', numNode 0, numInf 1, usrFlags 0x0, flags 0x5 }, ret gipcretKeyNotFound (36)
2014-05-20 11:04:02.563: [GIPCHGEN][154781440] gipchaResolveF [gipcmodGipcResolve : gipcmodGipc.c : 806]:
EXCEPTION[ ret gipcretKeyNotFound (36) ] failed to resolve ctx 0x2ed3940 [0000000000000010] { gipchaContext :
host 'grac41', name 'd541-9a1e-7807-8f4a', luid 'f733b93a-00000000', numNode 0, numInf 1, usrFlags 0x0, flags 0x5 },
host 'grac41', port 'ffac-854b-c525-6f9c', flags 0x0
--> Both request trying to use a host name.
If this isn't resolved we very likely have a Name server problem !
TraceFileName: ./grac41/ohasd/ohasd.log reports
2014-05-20 11:03:21.364: [GIPCXCPT][2905085696]gipchaInternalReadGpnp: No network info configured in GPNP,
using defaults, ret gipcretFail (1)
TraceFileName: ./evmd/evmd.log
2014-05-13 15:01:00.690: [ OCRMSG][2621794080]prom_waitconnect: CONN NOT ESTABLISHED (0,29,1,2)
2014-05-13 15:01:00.690: [ OCRMSG][2621794080]GIPC error [29] msg [gipcretConnectionRefused]
2014-05-13 15:01:00.690: [ OCRMSG][2621794080]prom_connect: error while waiting for connection complete [24]
2014-05-13 15:01:00.690: [ CRSOCR][2621794080] OCR context init failure.
Error: PROC-32: Cluster Ready Services on the local node
TraceFileName: ./grac41/gpnpd/gpnpd.log
2014-05-22 11:18:02.209: [ OCRCLI][1738393344]proac_con_init: Local listener using IPC. [(ADDRESS=(PROTOCOL=ipc)(KEY=procr_local_conn_0_PROC))]
2014-05-22 11:18:02.209: [ OCRMSG][1738393344]prom_waitconnect: CONN NOT ESTABLISHED (0,29,1,2)
2014-05-22 11:18:02.209: [ OCRMSG][1738393344]GIPC error [29] msg [gipcretConnectionRefused]
2014-05-22 11:18:02.209: [ OCRMSG][1738393344]prom_connect: error while waiting for connection complete [24]
2014-05-22 11:18:02.209: [ OCRCLI][1738393344]proac_con_init: Failed to connect to server [24]
2014-05-22 11:18:02.209: [ OCRCLI][1738393344]proac_con_init: Post sema. Con count [1]
[ OCRCLI][1738393344]ac_init:2: Could not initialize con structures. proac_con_init failed with [32]
Debug problem using cluvfy
[grid@grac42 ~]$ cluvfy comp nodereach -n grac41
Verifying node reachability
Checking node reachability...
PRVF-6006 : Unable to reach any of the nodes
PRKN-1034 : Failed to retrieve IP address of host "grac41"
==> Confirmation that we have a Name Server problem
Verification of node reachability was unsuccessful on all the specified nodes.
[grid@grac42 ~]$ cluvfy comp nodecon -n grac41
Verifying node connectivity
ERROR:
PRVF-6006 : Unable to reach any of the nodes
PRKN-1034 : Failed to retrieve IP address of host "grac41"
Verification cannot proceed
Verification of node connectivity was unsuccessful on all the specified nodes.
Debug problem with OS comands like ping and nslookup
==> For futher details see GENERIC Networking troubleshooting chapter
Case #2 : Private Interface down or wrong IP address- CSSD not starting
Reported Clusterware Error in CW alert.log: [/u01/app/11204/grid/bin/cssdagent(16445)]
CRS-5818:Aborted command 'start' for resource 'ora.cssd'.
Reported in ocssd.log : [ CSSD][491194112]clssnmvDHBValidateNcopy:
node 1, grac41, has a disk HB, but no network HB,
Reported in crfmond.log : [ CRFM][4239771392]crfm_connect_to:
Wait failed with gipcret: 16 for conaddr tcp://192.168.2.103:61020
Testing scenario :
Shutdown private interface
[root@grac42 ~]# ifconfig eth2 down
[root@grac42 ~]# ifconfig eth2
eth2 Link encap:Ethernet HWaddr 08:00:27:DF:79:B9
BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:754556 errors:0 dropped:0 overruns:0 frame:0
TX packets:631900 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:378302114 (360.7 MiB) TX bytes:221328282 (211.0 MiB)
[root@grac42 ~]# crsctl start crs
CRS-4123: Oracle High Availability Services has been started.
Clusterware status :
[root@grac42 grac42]# crsctl check crs
CRS-4638: Oracle High Availability Services is online
CRS-4535: Cannot communicate with Cluster Ready Services
CRS-4530: Communications failure contacting Cluster Synchronization Services daemon
CRS-4534: Cannot communicate with Event Manager
[grid@grac42 grac42]$ crsi
NAME TARGET STATE SERVER STATE_DETAILS
------------------------- ---------- ---------- ------------ ------------------
ora.asm ONLINE OFFLINE grac41 Instance Shutdown
ora.cluster_interconnect.haip ONLINE OFFLINE
ora.crf ONLINE ONLINE grac42
ora.crsd ONLINE OFFLINE
ora.cssd ONLINE OFFLINE STARTING
ora.cssdmonitor ONLINE ONLINE grac42
ora.ctssd ONLINE OFFLINE
ora.diskmon OFFLINE OFFLINE
ora.drivers.acfs ONLINE OFFLINE
ora.evmd ONLINE OFFLINE
ora.gipcd ONLINE ONLINE grac42
ora.gpnpd ONLINE ONLINE grac42
ora.mdnsd ONLINE ONLINE grac42
--> CSSD in mode STARTING and not progressing over time
After some minutes CSSD goes OFFLINE
Tracefile Details:
alertgrac42.log:
[cssd(16469)]CRS-1656:The CSS daemon is terminating due to a fatal error;
Details at (:CSSSC00012:) in .../cssd/ocssd.log
2014-05-31 14:15:41.828:
[cssd(16469)]CRS-1603:CSSD on node grac42 shutdown by user.
2014-05-31 14:15:41.828:
[/u01/app/11204/grid/bin/cssdagent(16445)]CRS-5818:Aborted command 'start' for resource 'ora.cssd'.
Details at (:CRSAGF00113:) {0:0:2} in ../agent/ohasd/oracssdagent_root/oracssdagent_root.log.
ocssd.log:
2014-05-31 14:23:11.534: [ CSSD][491194112]clssnmvDHBValidateNcopy: node 1, grac41,
has a disk HB, but no network HB,
DHB has rcfg 296672934, wrtcnt, 25000048, LATS 9730774, lastSeqNo 25000045,
uniqueness 1401378465, timestamp 1401538986/54631634
2014-05-31 14:23:11.550: [ CSSD][481683200]clssnmvDHBValidateNcopy: node 1, grac41,
has a disk HB, but no network HB,
DHB has rcfg 296672934, wrtcnt, 25000050, LATS 9730794, lastSeqNo 25000047,
uniqueness 1401378465, timestamp 1401538986/54632024
Using grep to locate errors
CRF resource is checking CI every 5s and reports errors:
$ fn.sh 2014-06-03 | egrep 'TraceFileName|failed'
TraceFileName: ./crfmond/crfmond.log
2014-06-03 08:28:40.859: [ CRFM][4239771392]crfm_connect_to:
Wait failed with gipcret: 16 for conaddr tcp://192.168.2.103:61020
2014-06-03 08:28:46.065: [ CRFM][4239771392]crfm_connect_to: Wait failed with gipcret: 16 for conaddr tcp://192.168.2.103:61020
2014-06-03 08:28:51.271: [ CRFM][4239771392]crfm_connect_to: Wait failed with gipcret: 16 for conaddr tcp://192.168.2.103:61020
2014-06-03 08:37:11.264: [ CSSCLNT][4243982080]clsssInitNative: connect to (ADDRESS=(PROTOCOL=ipc)(KEY=OCSSD_LL_grac42_)) failed, rc 13
DHB has rcfg 296672934, wrtcnt, 23890957, LATS 9730794, lastSeqNo 23890939, uniqueness 1401292202, timestamp 1401538981/89600384
Do we have any network problems ?
$ fn.sh "2014-06-03" | egrep 'but no network HB|TraceFileName'
Search String: no network HB
TraceFileName: ./cssd/ocssd.log
2014-06-02 12:51:52.564: [ CSSD][2682775296]clssnmvDHBValidateNcopy: node 3, grac43,
has a disk HB, but no network HB, DHB has rcfg 297162159, wrtcnt, 24036295, LATS 167224,
lastSeqNo 24036293, uniqueness 1401692525, timestamp 1401706311/13179394
2014-06-02 12:51:53.569: [ CSSD][2682775296]clssnmvDHBValidateNcopy: node 1, grac41,
has a disk HB, but no network HB, DHB has rcfg 297162159, wrtcnt, 25145340, LATS 168224,
lastSeqNo 25145334, uniqueness 1401692481, timestamp 1401706313/13192074
Is there a valid CI network device ?
# fn_egrep.sh "NETDATA" | egrep 'TraceFile|2014-06-03'
TraceFileName: ./gipcd/gipcd.log
2014-06-03 07:48:40.372: [ CLSINET][3977414400] Returning NETDATA: 1 interfaces
2014-06-03 07:48:45.401: [ CLSINET][3977414400] Returning NETDATA: 1 interfaces _-> ok
2014-06-03 07:52:51.589: [ CLSINET][1140848384] Returning NETDATA: 0 interfaces --> Problem with CI
2014-06-03 07:52:51.669: [ CLSINET][1492440832] Returning NETDATA: 0 interfaces
Debug with cluvfy
[grid@grac41 ~]$ cluvfy comp nodecon -n grac41,grac42 -i eth1,eth2
Verifying node connectivity
Checking node connectivity...
Checking hosts config file...
Verification of the hosts config file successful
ERROR:
PRVG-11049 : Interface "eth2" does not exist on nodes "grac42"
Check: Node connectivity for interface "eth1"
Node connectivity passed for interface "eth1"
TCP connectivity check passed for subnet "192.168.1.0"
Check: Node connectivity for interface "eth2"
Node connectivity failed for interface "eth2"
TCP connectivity check passed for subnet "192.168.2.0"
Checking subnet mask consistency...
Subnet mask consistency check passed for subnet "10.0.2.0".
Subnet mask consistency check passed for subnet "192.168.1.0".
Subnet mask consistency check passed for subnet "192.168.2.0".
Subnet mask consistency check passed for subnet "169.254.0.0".
Subnet mask consistency check passed for subnet "192.168.122.0".
Subnet mask consistency check passed.
Node connectivity check failed
Verification of node connectivity was unsuccessful on all the specified nodes.
Debug using OS commands
[grid@grac42 NET]$ /bin/ping -s 1500 -c 2 -I 192.168.2.102 192.168.2.101
bind: Cannot assign requested address
[grid@grac42 NET]$ /bin/ping -s 1500 -c 2 -I 192.168.2.102 192.168.2.102
bind: Cannot assign requested address
Verify GnpP profile and find out CI device
[root@grac42 crfmond]# $GRID_HOME/bin/gpnptool get 2>/dev/null | xmllint --format - | egrep 'CSS-Profile|ASM-Profile|Network id'
<gpnp:HostNetwork id="gen" HostName="*">
<gpnp:Network id="net1" IP="192.168.1.0" Adapter="eth1" Use="public"/>
<gpnp:Network id="net2" IP="192.168.2.0" Adapter="eth2" Use="cluster_interconnect"/>
--> eth2 is our cluster interconnect
[root@grac42 crfmond]# ifconfig eth2
eth2 Link encap:Ethernet HWaddr 08:00:27:DF:79:B9
inet addr:192.168.3.102 Bcast:192.168.3.255 Mask:255.255.255.0
inet6 addr: fe80::a00:27ff:fedf:79b9/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
-> Here we have a wrong address 192.168.3.102 should be 192.168.2.102
Note CI device should have following flags : UP BROADCAST RUNNING MULTICAST
Case #3 : Public Interface down - Public network ora.net1.network not starting
Reported in ./agent/crsd/orarootagent_root/orarootagent_root.log
2014-05-31 11:58:27.899: [ AGFW][1829066496]{2:12808:5} Preparing START command for: ora.net1.network grac42 1
2014-05-31 11:58:27.969: [ AGFW][1829066496]{2:12808:5} ora.net1.network grac42 1 state changed from: STARTING to: UNKNOWN
2014-05-31 11:58:27.969: [ AGFW][1829066496]{2:12808:5} ora.net1.network grac42 1 would be continued to monitored!
Reported Clusterware Error in CW alert.log: no errors reported
Testing scenario :
- Shutdown public interface
[root@grac42 evmd]# ifconfig eth1 down
[root@grac42 evmd]# ifconfig eth1
eth1 Link encap:Ethernet HWaddr 08:00:27:63:08:07
BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:2889 errors:0 dropped:0 overruns:0 frame:0
TX packets:2458 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:484535 (473.1 KiB) TX bytes:316359 (308.9 KiB)
[root@grac42 ~]# crsctl start crs
CRS-4123: Oracle High Availability Services has been started.
Clusterware status :
[grid@grac42 grac42]$ crsctl check crs
CRS-4638: Oracle High Availability Services is online
CRS-4537: Cluster Ready Services is online
CRS-4529: Cluster Synchronization Services is online
CRS-4533: Event Manager is online
--> OHASD stack is ok !
[grid@grac42 grac42]$ crsi
NAME TARGET STATE SERVER STATE_DETAILS
------------------------- ---------- ---------- ------------ ------------------
ora.asm ONLINE ONLINE grac42 Started
ora.cluster_interconnect.haip ONLINE ONLINE grac42
ora.crf ONLINE ONLINE grac42
ora.crsd ONLINE ONLINE grac42
ora.cssd ONLINE ONLINE grac42
ora.cssdmonitor ONLINE ONLINE grac42
ora.ctssd ONLINE ONLINE grac42 OBSERVER
ora.diskmon OFFLINE OFFLINE
ora.drivers.acfs ONLINE ONLINE grac42
ora.evmd ONLINE ONLINE grac42
ora.gipcd ONLINE ONLINE grac42
ora.gpnpd ONLINE ONLINE grac42
ora.mdnsd ONLINE ONLINE grac42
--> OAHSD stack is up and running
[grid@grac42 grac42]$ crs | grep grac42
NAME TARGET STATE SERVER STATE_DETAILS
------------------------- ---------- ---------- ------------ ------------------
ora.ASMLIB_DG.dg ONLINE ONLINE grac42
ora.DATA.dg ONLINE ONLINE grac42
ora.FRA.dg ONLINE ONLINE grac42
ora.LISTENER.lsnr ONLINE OFFLINE grac42
ora.OCR.dg ONLINE ONLINE grac42
ora.SSD.dg ONLINE ONLINE grac42
ora.asm ONLINE ONLINE grac42 Started
ora.gsd OFFLINE OFFLINE grac42
ora.net1.network ONLINE OFFLINE grac42
ora.ons ONLINE OFFLINE grac42
ora.registry.acfs ONLINE ONLINE grac42
ora.grac4.db ONLINE OFFLINE grac42 Instance Shutdown
ora.grac4.grac42.svc ONLINE OFFLINE grac42
ora.grac42.vip ONLINE INTERMEDIATE grac43 FAILED OVER
--> ora.net1.network OFFLINE
ora.grac42.vip n status INTERMEDIATE - FAILED OVER to grac43
Check messages logged for resource ora.net1.network from 2014-05-31 11:00:00 - 2014-05-31 11:59_59
[grid@grac42 grac42]$ fn.sh "ora.net1.network" | egrep '2014-05-31 11|TraceFileName'
TraceFileName: ./agent/crsd/orarootagent_root/orarootagent_root.log
2014-05-31 11:58:27.899: [ AGFW][1829066496]{2:12808:5} Agent received the message: RESOURCE_START[ora.net1.network grac42 1] ID 4098:403
2014-05-31 11:58:27.899: [ AGFW][1829066496]{2:12808:5} Preparing START command for: ora.net1.network grac42 1
2014-05-31 11:58:27.899: [ AGFW][1829066496]{2:12808:5} ora.net1.network grac42 1 state changed from: OFFLINE to: STARTING
2014-05-31 11:58:27.917: [ AGFW][1826965248]{2:12808:5} Command: start for resource: ora.net1.network grac42 1 completed with status: SUCCESS
2014-05-31 11:58:27.919: [ AGFW][1829066496]{2:12808:5} Agent sending reply for: RESOURCE_START[ora.net1.network grac42 1] ID 4098:403
2014-05-31 11:58:27.969: [ AGFW][1829066496]{2:12808:5} ora.net1.network grac42 1 state changed from: STARTING to: UNKNOWN
2014-05-31 11:58:27.969: [ AGFW][1829066496]{2:12808:5} ora.net1.network grac42 1 would be continued to monitored!
2014-05-31 11:58:27.969: [ AGFW][1829066496]{2:12808:5} Started implicit monitor for [ora.net1.network grac42 1] interval=1000 delay=1000
2014-05-31 11:58:27.969: [ AGFW][1829066496]{2:12808:5} Agent sending last reply for: RESOURCE_START[ora.net1.network grac42 1] ID 4098:403
2014-05-31 11:58:27.982: [ AGFW][1829066496]{2:12808:5} Agent received the message: RESOURCE_CLEAN[ora.net1.network grac42 1] ID 4100:409
2014-05-31 11:58:27.982: [ AGFW][1829066496]{2:12808:5} Preparing CLEAN command for: ora.net1.network grac42 1
2014-05-31 11:58:27.982: [ AGFW][1829066496]{2:12808:5} ora.net1.network grac42 1 state changed from: UNKNOWN to: CLEANING
2014-05-31 11:58:27.983: [ AGFW][1826965248]{2:12808:5} Command: clean for resource: ora.net1.network grac42 1 completed with status: SUCCESS
2014-05-31 11:58:27.984: [ AGFW][1829066496]{2:12808:5} Agent sending reply for: RESOURCE_CLEAN[ora.net1.network grac42 1] ID 4100:409
2014-05-31 11:58:27.984: [ AGFW][1829066496]{2:12808:5} ora.net1.network grac42 1 state changed from: CLEANING to: OFFLINE
Debug with cluvfy
Run cluvfy on the failing node
[grid@grac42 grac42]$ cluvfy comp nodereach -n grac42
Verifying node reachability
Checking node reachability...
PRVF-6006 : Unable to reach any of the nodes
PRKC-1071 : Nodes "grac42" did not respond to ping in "3" seconds,
PRKN-1035 : Host "grac42" is unreachable
Verification of node reachability was unsuccessful on all the specified nodes.
Debug with OS Commands
[grid@grac42 NET]$ /bin/ping -s 1500 -c 2 -I 192.168.1.102 grac42
bind: Cannot assign requested address
--> Here we are failing as eht1 is not up and running
[grid@grac42 NET]$ /bin/ping -s 1500 -c 2 -I 192.168.1.102 grac41
ping: unknown host grac41
--> Here we are failing due as Nameserver can be reached
Debugging complete CW startup with strace
-
-
- resource STATE remains STARTING for a long time
- resource process gets restarted quickly but could not successful start at all
- Note strace will only help for protection or connection issues.
- If there is a logical corruption you need to review CW log files
Command used as user root : # strace -t -f -o /tmp/ohasd.trc crsctl start crs
CW status : GPNP daemon doesn't come up
Verify OHASD stack
NAME TARGET STATE SERVER STATE_DETAILS
------------------------- ---------- ---------- ------------ ------------------
ora.asm ONLINE OFFLINE Instance Shutdown
ora.cluster_interconnect.haip ONLINE OFFLINE
ora.crf ONLINE OFFLINE
ora.crsd ONLINE OFFLINE
ora.cssd ONLINE OFFLINE
ora.cssdmonitor ONLINE OFFLINE
ora.ctssd ONLINE OFFLINE
ora.diskmon ONLINE OFFLINE
ora.drivers.acfs ONLINE ONLINE grac41
ora.evmd ONLINE OFFLINE
ora.gipcd ONLINE OFFLINE
ora.gpnpd ONLINE OFFLINE STARTING
ora.mdnsd ONLINE ONLINE grac41
--> gpnpd daemon does not progress over time : STATE shows STARTING
Now stop CW and restart CW startup with strace -t -f
[root@grac41 gpnpd]# strace -t -f -o /tmp/ohasd.trc crsctl start crs
[root@grac41 gpnpd]# grep -i gpnpd /tmp/ohasd.trc | more
Check whether gpnpd shell and gpnpd.bin were scheduled for running :
root@grac41 log]# grep -i execve /tmp/ohasd.trc | grep gpnp
9866 08:13:56 execve("/u01/app/11204/grid/bin/gpnpd", ["/u01/app/11204/grid/bin/gpnpd"], [/* 72 vars */] <unfinished ...>
9866 08:13:56 execve("/u01/app/11204/grid/bin/gpnpd.bin", ["/u01/app/11204/grid/bin/gpnpd.bi"...], [/* 72 vars */] <unfinished ...>
11017 08:16:01 execve("/u01/app/11204/grid/bin/gpnpd", ["/u01/app/11204/grid/bin/gpnpd"], [/* 72 vars */] <unfinished ...>
11017 08:16:01 execve("/u01/app/11204/grid/bin/gpnpd.bin", ["/u01/app/11204/grid/bin/gpnpd.bi"...], [/* 72 vars */] <unfinished ...>
--> gpnpd.bin was scheduled 2x in 5 seconeds - seems we have problem here check return codes
Check ohasd.trc for errors like:
$ egrep 'EACCES|ENOENT|EADDRINUSE|ECONNREFUSED|EPERM' /tmp/ohasd.trc
Check ohasd.trc for certain return codes
# grep EACCES /tmp/ohasd.trc
# grep ENOENT ohasd.trc # returns a lot of info
Linux error codes leading to a failed CW startup
EACCES :
open("/u01/app/11204/grid/log/grac41/gpnpd/gpnpdOUT.log", O_RDWR|O_CREAT|O_APPEND, 0644) = -1 EACCES (Permission denied)
ENOENT :
stat("/u01/app/11204/grid/log/grac41/ohasd", 0x7fff17d68f40) = -1 ENOENT (No such file or directory)
EADDRINUSE :
[pid 7391] bind(6, {sa_family=AF_FILE, path="/var/tmp/.oracle/sgrac41DBG_MDNSD"}, 110) = -1 EADDRINUSE (Address already in use)
ECONNREFUSED :
[pid 7391] connect(6, {sa_family=AF_FILE, path="/var/tmp/.oracle/sgrac41DBG_MDNSD"}, 110) = -1 ECONNREFUSED (Connection refused)
EPERM :
[pid 7391] unlink("/var/tmp/.oracle/sgrac41DBG_MDNSD") = -1 EPERM (Operation not permitted)
Check for LOGfile and PID file usage
PID file usage :
# grep "\.pid" ohasd.trc
Sucessful open of mdns/init/grac41.pid through MDSND
9848 08:13:55 stat("/u01/app/11204/grid/mdns/init/grac41.pid", <unfinished ...>
9848 08:13:55 stat("/u01/app/11204/grid/mdns/init/grac41.pid", <unfinished ...>
9848 08:13:55 access("/u01/app/11204/grid/mdns/init/grac41.pid", F_OK <unfinished ...>
9848 08:13:55 statfs("/u01/app/11204/grid/mdns/init/grac41.pid", <unfinished ...>
9848 08:13:55 open("/u01/app/11204/grid/mdns/init/grac41.pid", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 7
9841 08:13:56 stat("/u01/app/11204/grid/mdns/init/grac41.pid", {st_mode=S_IFREG|0644, st_size=5, ...}) = 0
9841 08:13:56 stat("/u01/app/11204/grid/mdns/init/grac41.pid", {st_mode=S_IFREG|0644, st_size=5, ...}) = 0
9841 08:13:56 access("/u01/app/11204/grid/mdns/init/grac41.pid", F_OK) = 0
9841 08:13:56 statfs("/u01/app/11204/grid/mdns/init/grac41.pid", {f_type="EXT2_SUPER_MAGIC", f_bsize=4096,
f_blocks=9900906, f_bfree=2564283, f_bavail=2061346, f_files=2514944, f_ffree=2079685, f_fsid={1657171729, 223082106}, f_namelen=255, f_frsize=4096}) = 0
9841 08:13:56 open("/u01/app/11204/grid/mdns/init/grac41.pid", O_RDONLY) = 27
9845 08:13:56 open("/var/tmp/.oracle/mdnsd.pid", O_WRONLY|O_CREAT|O_TRUNC, 0666 <unfinished ...>
Failed open of gpnp/init/grac41.pid through GPNPD
9842 08:16:00 stat("/u01/app/11204/grid/gpnp/init/grac41.pid", <unfinished ...>
9842 08:16:00 stat("/u01/app/11204/grid/gpnp/init/grac41.pid", <unfinished ...>
9842 08:16:00 access("/u01/app/11204/grid/gpnp/init/grac41.pid", F_OK <unfinished ...>
9842 08:16:00 statfs("/u01/app/11204/grid/gpnp/init/grac41.pid", <unfinished ...>
9842 08:16:00 open("/u01/app/11204/grid/gpnp/init/grac41.pid", O_RDONLY <unfinished ...>
9860 08:16:01 stat("/u01/app/11204/grid/gpnp/init/grac41.pid", <unfinished ...>
9860 08:16:01 stat("/u01/app/11204/grid/gpnp/init/grac41.pid", <unfinished ...>
9860 08:16:01 access("/u01/app/11204/grid/gpnp/init/grac41.pid", F_OK <unfinished ...>
9860 08:16:01 statfs("/u01/app/11204/grid/gpnp/init/grac41.pid", <unfinished ...>
9860 08:16:01 open("/u01/app/11204/grid/gpnp/init/grac41.pid", O_RDONLY <unfinished ...>
Sucessful open of Logfile log/grac41/mdnsd/mdnsd.log through MDSND
# grep "\.log" /tmp/ohasd.trc # this on is very helplful
9845 08:13:55 open("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", O_WRONLY|O_APPEND) = 4
9845 08:13:55 stat("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", {st_mode=S_IFREG|0644, st_size=509983, ...}) = 0
9845 08:13:55 chmod("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", 0644) = 0
9845 08:13:55 stat("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", {st_mode=S_IFREG|0644, st_size=509983, ...}) = 0
9845 08:13:55 chmod("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", 0644) = 0
9845 08:13:55 stat("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", {st_mode=S_IFREG|0644, st_size=509983, ...}) = 0
9845 08:13:55 stat("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", {st_mode=S_IFREG|0644, st_size=509983, ...}) = 0
9845 08:13:55 access("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", F_OK) = 0
9845 08:13:55 statfs("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", {f_type="EXT2_SUPER_MAGIC", f_bsize=4096, f_blocks=9900906,
f_bfree=2564312, f_bavail=2061375, f_files=2514944, f_ffree=2079685, f_fsid={1657171729, 223082106}, f_namelen=255, f_frsize=4096}) = 0
9845 08:13:55 open("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", O_WRONLY|O_APPEND) = 4
9845 08:13:55 stat("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", {st_mode=S_IFREG|0644, st_size=509983, ...}) = 0
9845 08:13:55 stat("/u01/app/11204/grid/log/grac41/mdnsd/mdnsd.log", <unfinished ...>
Failed open of Logfile log/grac41/gpnpd/gpnpdOUT.log and through GPNPD
9866 08:13:56 open("/u01/app/11204/grid/log/grac41/gpnpd/gpnpdOUT.log", O_RDWR|O_CREAT|O_APPEND, 0644 <unfinished ...>
--> We need to get a file descriptor back from open call
9842 08:15:56 stat("/u01/app/11204/grid/log/grac41/alertgrac41.log", {st_mode=S_IFREG|0664, st_size=1877580, ...}) = 0
9842 08:15:56 stat("/u01/app/11204/grid/log/grac41/alertgrac41.log", {st_mode=S_IFREG|0664, st_size=1877580, ...}) = 0
Checking IPC sockets usage
Succesfull opening of IPC sockets throuph of MSDMD process
# grep MDNSD /tmp/ohasd.trc
9849 08:13:56 chmod("/var/tmp/.oracle/sgrac41DBG_MDNSD", 0777) = 0
9862 08:13:56 access("/var/tmp/.oracle/sgrac41DBG_MDNSD", F_OK <unfinished ...>
9862 08:13:56 connect(28, {sa_family=AF_FILE, path="/var/tmp/.oracle/sgrac41DBG_MDNSD"}, 110 <unfinished ...>
9849 08:13:56 <... getsockname resumed> {sa_family=AF_FILE, path="/var/tmp/.oracle/sgrac41DBG_MDNSD"}, [36]) = 0
9849 08:13:56 chmod("/var/tmp/.oracle/sgrac41DBG_MDNSD", 0777 <unfinished ...>
--> connect was successfull at 13:56 - further processing with system calls like bind() will be seend in trace
No furhter connect requests are happing for /var/tmp/.oracle/sgrac41DBG_MDNSD
Complete log including a successful connect
9862 08:13:56 connect(28, {sa_family=AF_FILE, path="/var/tmp/.oracle/sgrac41DBG_MDNSD"}, 110 <unfinished ...>
9834 08:13:56 <... times resumed> {tms_utime=3, tms_stime=4, tms_cutime=0, tms_cstime=0}) = 435715860
9862 08:13:56 <... connect resumed> ) = 0
9862 08:13:56 connect(28, {sa_family=AF_FILE, path="/var/tmp/.oracle/sgrac41DBG_MDNSD"}, 110 <unfinished ...>
9834 08:13:56 <... times resumed> {tms_utime=3, tms_stime=4, tms_cutime=0, tms_cstime=0}) = 435715860
9862 08:13:56 <... connect resumed> ) = 0
..
9849 08:13:55 bind(6, {sa_family=AF_FILE, path="/var/tmp/.oracle/sgrac41DBG_MDNSD"}, 110) = 0
..
9849 08:13:55 listen(6, 500 <unfinished ...>
9731 08:13:55 nanosleep({0, 1000000}, <unfinished ...>
9849 08:13:55 <... listen resumed> ) = 0
--> After a successfull listen system call clients can connect
To allow clients to connect we need as succesful connect(), bind() and listen() system call !
Failed opening of IPC sockets throuph of GPNPD process
# grep MDNSD /tmp/ohasd.trc
9924 08:14:37 access("/var/tmp/.oracle/sgrac41DBG_GPNPD", F_OK) = 0
9924 08:14:37 connect(30, {sa_family=AF_FILE, path="/var/tmp/.oracle/sgrac41DBG_GPNPD"}, 110)
= -1 ECONNREFUSED (Connection refused)
9924 08:14:37 access("/var/tmp/.oracle/sgrac41DBG_GPNPD", F_OK) = 0
9924 08:14:37 connect(30, {sa_family=AF_FILE, path="/var/tmp/.oracle/sgrac41DBG_GPNPD"}, 110) =
= -1 ECONNREFUSED (Connection refused)
--> The connect request was unsucssful and was repeated again and again.
Debugging a single CW process with strace
-
-
- resource STATE remains STARTING for a long time
- resource process gets restarted quickly but could not succesfully start at all
- Note strace will only help for protection or connection issues.
- If there is a logical corruption you need to review CW log files
[root@grac41 .oracle]# crsi
NAME TARGET STATE SERVER STATE_DETAILS
------------------------- ---------- ---------- ------------ ------------------
ora.asm ONLINE OFFLINE Instance Shutdown
ora.cluster_interconnect.haip ONLINE OFFLINE
ora.crf ONLINE OFFLINE
ora.crsd ONLINE OFFLINE
ora.cssd ONLINE OFFLINE
ora.cssdmonitor ONLINE OFFLINE
ora.ctssd ONLINE OFFLINE
ora.diskmon ONLINE OFFLINE
ora.drivers.acfs ONLINE OFFLINE
ora.evmd ONLINE OFFLINE
ora.gipcd ONLINE OFFLINE
ora.gpnpd ONLINE OFFLINE STARTING
ora.mdnsd ONLINE ONLINE grac41
Check whether the related process is running ?
[root@grac41 .oracle]# ps -elf | egrep "PID|d.bin|ohas|oraagent|orarootagent|cssdagent|cssdmonitor" | grep -v grep
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 7023 1 0 80 0 - 2846 pipe_w 06:01 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run
0 S grid 17764 10515 0 80 0 - 1113 wait 12:11 pts/8 00:00:00 strace -t -f -o /tmp/mdnsd.trc /u01/app/11204/grid/bin/mdnsd
0 S grid 17767 17764 0 80 0 - 78862 poll_s 12:11 ? 00:00:00 /u01/app/11204/grid/bin/mdnsd.bin
4 S root 18501 1 23 80 0 - 176836 futex_ 12:13 ? 00:05:07 /u01/app/11204/grid/bin/ohasd.bin reboot
4 S grid 18567 1 1 80 0 - 170697 futex_ 12:13 ? 00:00:14 /u01/app/11204/grid/bin/oraagent.bin
4 S root 20306 1 0 -40 - - 160927 futex_ 12:19 ? 00:00:03 /u01/app/11204/grid/bin/cssdmonitor
4 S root 21396 1 0 80 0 - 163115 futex_ 12:23 ? 00:00:00 /u01/app/11204/grid/bin/orarootagent.bin
--> gpnpd.bin is not running - but was restarted very often
Starting gpnpd.bin process with strace : $ strace -t -f -o /tmp/gpnpd.trc /u01/app/11204/grid/bin/gpnpd
Note this is very very dangerous as you need to know which user start this process
IF you run this procless as the wrong user OLR,OCR, IPC sockest privs and log file location can we corrupted !
Before tracing a single process you may run strace -t -f -o ohasd.trc crsctl start crs ( see the above chapater )
as this command alwas starts the process as correct user, in correct order and pull up needed resources
Run the following commands only our your test system as a last ressort.
Manually start gpnpd as user grid with strace attached!
[grid@grac41 grac41]$ strace -t -f -o /tmp/gpnpd.trc /u01/app/11204/grid/bin/gpnpd
Unable to open file /u01/app/11204/grid/log/grac41/gpnpd/gpnpdOUT.log: %
[grid@grac41 grac41]$ egrep 'EACCES|ENOENT|EADDRINUSE|ECONNREFUSED|EPERM' /tmp/gpnpd.trc
25251 12:37:39 open("/u01/app/11204/grid/log/grac41/gpnpd/gpnpdOUT.log",
O_RDWR|O_CREAT|O_APPEND, 0644) = -1 EACCES (Permission denied)
-==> Fix: # chown grid:oinstall /u01/app/11204/grid/log/grac41/gpnpd/gpnpdOUT.log
Repeat the above command as long we errors
[grid@grac41 grac41]$ strace -t -f -o /tmp/gpnpd.trc /u01/app/11204/grid/bin/gpnpd
[grid@grac41 grac41]$ egrep 'EACCES|ENOENT|EADDRINUSE|ECONNREFUSED|EPERM' /tmp/gpnpd.trc
27089 12:44:35 connect(45, {sa_family=AF_FILE, path="/var/tmp/.oracle/sprocr_local_conn_0_PROC"}, 110) =
= -1 ENOENT (No such file or directory)
27089 12:44:58 connect(45, {sa_family=AF_FILE, path="/var/tmp/.oracle/sprocr_local_conn_0_PROC"}, 110)
= -1 ENOENT (No such file or directory)
..
32486 13:03:52 connect(45, {sa_family=AF_FILE, path="/var/tmp/.oracle/sprocr_local_conn_0_PROC"}, 110)
= -1 ENOENT (No such file or directory)
--> Connect was unsuccesfull - check IPC socket protections !
Note strace will only help for protection or connection issues.
If there is a logical corruption you need to review CW log files
Details of a logical OCR corruption with PROCL-5 error : ./gpnpd/gpnpd.log
..
[ CLWAL][3606726432]clsw_Initialize: OLR initlevel [70000]
[ OCRAPI][3606726432]a_init:10: AUTH LOC [/u01/app/11204/grid/srvm/auth]
[ OCRMSG][3606726432]prom_init: Successfully registered comp [OCRMSG] in clsd.
2014-05-20 07:57:51.118: [ OCRAPI][3606726432]a_init:11: Messaging init successful.
[ OCRCLI][3606726432]oac_init: Successfully registered comp [OCRCLI] in clsd.
2014-05-20 07:57:51.118: [ OCRCLI][3606726432]proac_con_init: Local listener using IPC. [(ADDRESS=(PROTOCOL=ipc)(KEY=procr_local_conn_0_PROL))]
2014-05-20 07:57:51.119: [ OCRCLI][3606726432]proac_con_init: Successfully connected to the server
2014-05-20 07:57:51.119: [ OCRCLI][3606726432]proac_con_init: Post sema. Con count [1]
2014-05-20 07:57:51.120: [ OCRAPI][3606726432]a_init:12: Client init successful.
2014-05-20 07:57:51.120: [ OCRAPI][3606726432]a_init:21: OCR init successful. Init Level [7]
2014-05-20 07:57:51.120: [ OCRAPI][3606726432]a_init:2: Init Level [7]
2014-05-20 07:57:51.132: [ OCRCLI][3606726432]proac_con_init: Post sema. Con count [2]
[ clsdmt][3595089664]Listening to (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_GPNPD))
2014-05-20 07:57:51.133: [ clsdmt][3595089664]PID for the Process [31034], connkey 10
2014-05-20 07:57:51.133: [ clsdmt][3595089664]Creating PID [31034] file for home /u01/app/11204/grid host grac41 bin gpnp to /u01/app/11204/grid/gpnp/init/
2014-05-20 07:57:51.133: [ clsdmt][3595089664]Writing PID [31034] to the file [/u01/app/11204/grid/gpnp/init/grac41.pid]
2014-05-20 07:57:52.108: [ GPNP][3606726432]clsgpnpd_validateProfile: [at clsgpnpd.c:2919] GPnPD taken cluster name 'grac4'
2014-05-20 07:57:52.108: [ GPNP][3606726432]clsgpnpd_openLocalProfile: [at clsgpnpd.c:3477] Got local profile from file cache provider (LCP-FS).
2014-05-20 07:57:52.111: [ GPNP][3606726432]clsgpnpd_openLocalProfile: [at clsgpnpd.c:3532] Got local profile from OLR cache provider (LCP-OLR).
2014-05-20 07:57:52.113: [ GPNP][3606726432]procr_open_key_ext: OLR api procr_open_key_ext failed for key SYSTEM.GPnP.profiles.peer.pending
2014-05-20 07:57:52.113: [ GPNP][3606726432]procr_open_key_ext: OLR current boot level : 7
2014-05-20 07:57:52.113: [ GPNP][3606726432]procr_open_key_ext: OLR error code : 5
2014-05-20 07:57:52.126: [ GPNP][3606726432]procr_open_key_ext: OLR error message : PROCL-5: User does not have permission to perform a local registry operation on this key.
Authentication error [User does not have permission to perform this operation] [0]
2014-05-20 07:57:52.126: [ GPNP][3606726432]clsgpnpco_ocr2profile: [at clsgpnpco.c:578] Result: (58) CLSGPNP_OCR_ERR. Failed to open requested OLR Profile.
2014-05-20 07:57:52.127: [ GPNP][3606726432]clsgpnpd_lOpen: [at clsgpnpd.c:1734] Listening on ipc://GPNPD_grac41
2014-05-20 07:57:52.127: [ GPNP][3606726432]clsgpnpd_lOpen: [at clsgpnpd.c:1743] GIPC gipcretFail (1) gipcListen listen failure on
2014-05-20 07:57:52.127: [ default][3606726432]GPNPD failed to start listening for GPnP peers.
2014-05-20 07:57:52.135: [ GPNP][3606726432]clsgpnpd_term: [at clsgpnpd.c:1344] STOP GPnPD terminating. Closing connections...
2014-05-20 07:57:52.137: [ default][3606726432]clsgpnpd_term STOP terminating.
2014-05-20 07:57:53.136: [ OCRAPI][3606726432]a_terminate:1:current ref count = 1
2014-05-20 07:57:53.136: [ OCRAPI][3606726432]a_terminate:1:current ref count = 0
--> Fatal OLR error ==> OLR is corrupted ==> GPnPD terminating .
For details how to fix PROCL-5 error please read following link.
OHASD does not start
Understanding CW startup configuration in OEL 6
OHASD Script location
[root@grac41 init.d]# find /etc |grep S96
/etc/rc.d/rc5.d/S96ohasd
/etc/rc.d/rc3.d/S96ohasd
[root@grac41 init.d]# ls -l /etc/rc.d/rc5.d/S96ohasd
lrwxrwxrwx. 1 root root 17 May 4 10:57 /etc/rc.d/rc5.d/S96ohasd -> /etc/init.d/ohasd
[root@grac41 init.d]# ls -l /etc/rc.d/rc3.d/S96ohasd
lrwxrwxrwx. 1 root root 17 May 4 10:57 /etc/rc.d/rc3.d/S96ohasd -> /etc/init.d/ohasd
--> Run level 3 and 5 should start ohasd daemon
Check status of init.ohasd process
[root@grac41 bin]# more /etc/init/oracle-ohasd.conf
# Copyright (c) 2001, 2011, Oracle and/or its affiliates. All rights reserved.
#
# Oracle OHASD startup
start on runlevel [35]
stop on runlevel [!35]
respawn
exec /etc/init.d/init.ohasd run >/dev/null 2>&1 </dev/null
List current PID
[root@grac41 Desktop]# initctl list | grep oracle-ohasd
oracle-ohasd start/running, process 27558
[root@grac41 Desktop]# ps -elf | egrep "PID|d.bin|ohas|oraagent|orarootagent|cssdagent|cssdmonitor" | grep -v grep
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 27558 1 0 80 0 - 2878 wait 07:01 ? 00:00:02 /bin/sh /etc/init.d/init.ohasd run
Case #1 : OHASD does not start
Check your runlevel, running init.ohasd process and clusterware configuration
# who -r
run-level 5 2014-05-19 14:48
# ps -elf | egrep "PID|d.bin|ohas" | grep -v grep
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 6098 1 0 80 0 - 2846 wait 04:44 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run
# crsctl config crs
CRS-4622: Oracle High Availability Services autostart is enabled.
Case #2 : OLR not accessilbe - CW doesn't start - Error CRS-4124
Reported error in ocssd.log :
Reported Clusterware Error in CW alert.log: CRS-0704:Oracle High Availability Service aborted due to Oracle Local Registry error
[PROCL-33: Oracle Local Registry is not configured Storage layer error
[Error opening olr.loc file. No such file or directory] [2]].
Details at (:OHAS00106:) in /u01/app/11204/grid/log/grac41/ohasd/ohasd.log.
Testing scenario :
# mv /etc/oracle/olr.loc /etc/oracle/olr.loc_bck
# crsctl start crs
CRS-4124: Oracle High Availability Services startup failed.
CRS-4000: Command Start failed, or completed with errors.
Clusterware status :
# crsi
NAME TARGET STATE SERVER STATE_DETAILS
------------------------- ---------- ---------- ------------ ------------------
CRS-4639: Could not contact Oracle
CRS-4000: Command Status failed, or
[root@grac41 Desktop]# ps -elf | egrep "PID|d.bin|ohas" | grep -v grep
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 6098 1 0 80 0 - 2846 wait 04:44 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run
--> OHASD.bin does not start
Tracefile Details:
./grac41/alertgrac41.log
[ohasd(20436)]CRS-0704:Oracle High Availability Service aborted due to Oracle Local Registry error
[PROCL-33: Oracle Local Registry is not configured Storage layer error [Error opening olr.loc file. No such file or directory] [2]].
Details at (:OHAS00106:) in /u01/app/11204/grid/log/grac41/ohasd/ohasd.log.
./grac41/ohasd/ohasd.log
2014-05-11 11:45:42.892: [ CRSOCR][149608224] OCR context init failure. Error: PROCL-33: Oracle Local Registry is not configured Storage layer error
[Error opening olr.loc file. No such file or directory] [2]
2014-05-11 11:45:42.893: [ default][149608224] Created alert : (:OHAS00106:) : OLR initialization failed, error:
PROCL-33: Oracle Local Registry is not configured Storage layer error
[Error opening olr.loc file. No such file or directory] [2]
2014-05-11 11:45:42.893: [ default][149608224][PANIC] OHASD exiting; Could not init OLR
2014-05-11 11:45:42.893: [ default][149608224] Done.
OS log : /var/log/messages
May 24 09:21:53 grac41 clsecho: /etc/init.d/init.ohasd: Ohasd restarts 11 times in 2 seconds.
May 24 09:21:53 grac41 clsecho: /etc/init.d/init.ohasd: Ohasd restarts too rapidly. Stop auto-restarting.
Debugging steps
Verify your local Cluster repository
# ocrcheck -local -config
PROTL-604: Failed to retrieve the configured location of the local registry
Error opening olr.loc file. No such file or directory
# ocrcheck -local
PROTL-601: Failed to initialize ocrcheck
PROCL-33: Oracle Local Registry is not configured Storage layer error [Error opening olr.loc file. No such file or directory] [2]
# ls -l /etc/oracle/olr.loc
ls: cannot access /etc/oracle/olr.loc: No such file or directory
Note a working OLR should look like:
# more /etc/oracle/olr.loc
olrconfig_loc=/u01/app/11204/grid/cdata/grac41.olr
crs_home=/u01/app/11204/grid
# ls -l /u01/app/11204/grid/cdata/grac41.olr
-rw-------. 1 root oinstall 272756736 May 24 09:15 /u01/app/11204/grid/cdata/grac41.olr
Verify your OLR configuration with cluvfy
[grid@grac41 ~]$ cluvfy comp olr -verbose
ERROR:
Oracle Grid Infrastructure not configured.
You cannot run '/u01/app/11204/grid/bin/cluvfy' without the Oracle Grid Infrastructure.
Strace the command to get more details:
[grid@grac41 crsd]$ strace -t -f -o clu.trc cluvfy comp olr -verbose
clu.trc reports :
29993 09:32:19 open("/etc/oracle/olr.loc", O_RDONLY) = -1 ENOENT (No such file or directory)
OHASD Agents do not start
-
-
- OHASD.BIN will spawn four agents/monitors to start resource:
- oraagent: responsible for ora.asm, ora.evmd, ora.gipcd, ora.gpnpd, ora.mdnsd etc
- orarootagent: responsible for ora.crsd, ora.ctssd, ora.diskmon, ora.drivers.acfs etc
- cssdagent / cssdmonitor: responsible for ora.cssd(for ocssd.bin) and ora.cssdmonitor(for cssdmonitor itself)
If ohasd.bin can not start any of above agents properly, clusterware will not come to healthy state.
Potential Problems
1. Common causes of agent failure are that the log file or log directory for the agents don't have proper ownership or permission.
2. If agent binary (oraagent.bin or orarootagent.bin etc) is corrupted, agent will not start resulting in related resources not coming up:
Debugging CRS startup if trace file location is not accessible
Action - Change trace directory
[grid@grac41 log]$ mv $GRID_HOME/log/grac41 $GRID_HOME/log/grac41_nw
[grid@grac41 log]$ crsctl start crs
CRS-4124: Oracle High Availability Services startup failed.
CRS-4000: Command Start failed, or completed with errors.
Process Status and CRS status
[root@grac41 .oracle]# ps -elf | egrep "PID|d.bin|ohas|oraagent|orarootagent|cssdagent|cssdmonitor" | grep -v grep
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 5396 1 0 80 0 - 2847 pipe_w 10:52 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run
4 S root 26705 25370 1 80 0 - 47207 hrtime 14:05 pts/7 00:00:00 /u01/app/11204/grid/bin/crsctl.bin start crs
[root@grac41 .oracle]# crsctl check crs
CRS-4639: Could not contact Oracle High Availability Services
OS Tracefile: /var/log/messages
May 13 13:48:27 grac41 root: exec /u01/app/11204/grid/perl/bin/perl -I/u01/app/11204/grid/perl/lib
/u01/app/11204/grid/bin/crswrapexece.pl
/u01/app/11204/grid/crs/install/s_crsconfig_grac41_env.txt /u01/app/11204/grid/bin/ohasd.bin "reboot"
May 13 13:48:27 grac41 OHASD[22203]: OHASD exiting; Directory /u01/app/11204/grid/log/grac41/ohasd not found
Debugging steps
[root@grac41 gpnpd]# strace -f -o ohas.trc crsctl start crs
CRS-4124: Oracle High Availability Services startup failed.
CRS-4000: Command Start failed, or completed with errors.
[root@grac41 gpnpd]# grep ohasd ohas.trc
...
22203 execve("/u01/app/11204/grid/bin/ohasd.bin", ["/u01/app/11204/grid/bin/ohasd.bi"..., "reboot"], [/* 60 vars */]) = 0
22203 stat("/u01/app/11204/grid/log/grac41/ohasd", 0x7fff17d68f40) = -1 ENOENT (No such file or directory)
==> Directory /u01/app/11204/grid/log/grac41/ohasd was missing or has wrong protection
Using clufy comp olr
[grid@grac41 ~]$ cluvfy comp olr
Verifying OLR integrity
Checking OLR integrity...
Checking OLR config file...
ERROR:
2014-05-17 18:26:41.576: CLSD: A file system error occurred while attempting to create default permissions for
file "/u01/app/11204/grid/log/grac41/alertgrac41.log" during alert open processing for
process "client". Additional diagnostics:
LFI-00133: Trying to create file /u01/app/11204/grid/log/grac41/alertgrac41.log
that already exists.
LFI-01517: open() failed(OSD return value = 13).
2014-05-17 18:26:41.585: CLSD: An error was encountered while attempting to
open alert log "/u01/app/11204/grid/log/grac41/alertgrac41.log".
Additional diagnostics: (:CLSD00155:) 2014-05-17 18:26:41.585:
OLR config file check successful
Checking OLR file attributes...
ERROR:
PRVF-4187 : OLR file check failed on the following nodes:
grac41
grac41:PRVF-4127 : Unable to obtain OLR location
/u01/app/11204/grid/bin/ocrcheck -config -local
<CV_CMD>/u01/app/11204/grid/bin/ocrcheck -config -local </CV_CMD><CV_VAL>2014-05-17 18:26:45.202:
CLSD: A file system error occurred while attempting to create default permissions for file
"/u01/app/11204/grid/log/grac41/alertgrac41.log" during alert open processing for process "client".
Additional diagnostics: LFI-00133: Trying to create file /u01/app/11204/grid/log/grac41/alertgrac41.log
that already exists.
LFI-01517: open() failed(OSD return value = 13).
2014-05-17 18:26:45.202:
CLSD: An error was encountered while attempting to open alert log
"/u01/app/11204/grid/log/grac41/alertgrac41.log". Additional diagnostics: (:CLSD00155:)
2014-05-17 18:26:45.202:
CLSD: Alert logging terminated for process client. File name: "/u01/app/11204/grid/log/grac41/alertgrac41.log"
2014-05-17 18:26:45.202:
CLSD: A file system error occurred while attempting to create default permissions for file
"/u01/app/11204/grid/log/grac41/client/ocrcheck_7617.log" during log open processing for process "client".
Additional diagnostics: LFI-00133: Trying to create file /u01/app/11204/grid/log/grac41/client/ocrcheck_7617.log
that already exists.
LFI-01517: open() failed(OSD return value = 13).
2014-05-17 18:26:45.202:
CLSD: An error was encounteredcluvfy comp gpnp while attempting to open log file
"/u01/app/11204/grid/log/grac41/client/ocrcheck_7617.log".
Additional diagnostics: (:CLSD00153:)
2014-05-17 18:26:45.202:
CLSD: Logging terminated for process client. File name: "/u01/app/11204/grid/log/grac41/client/ocrcheck_7617.log"
Oracle Local Registry configuration is :
Device/File Name : /u01/app/11204/grid/cdata/grac41.olr
</CV_VAL><CV_VRES>0</CV_VRES><CV_LOG>Exectask: runexe was successful</CV_LOG><CV_ERES>0</CV_ERES>
OLR integrity check failed
Verification of OLR integrity was unsuccessful.
OCSSD.BIN does not start
Case #1 : GPnP profile is not accessible - gpnpd needs to be fully up to serve profile
Grep option to search traces :
$ fn_egrep.sh "Cannot get GPnP profile|Error put-profile CALL"
TraceFileName: ./grac41/agent/ohasd/orarootagent_root/orarootagent_root.log
2014-05-20 10:26:44.532: [ default][1199552256]Cannot get GPnP profile.
Error CLSGPNP_NO_DAEMON (GPNPD daemon is not running).
Cannot get GPnP profile
2014-04-21 15:27:06.838: [ GPNP][132114176]clsgpnp_profileCallUrlInt: [at clsgpnp.c:2243]
Result: (13) CLSGPNP_NO_DAEMON.
Error put-profile CALL to remote "tcp://grac41:56376"
disco "mdns:service:gpnp._tcp.local.://grac41:56376/agent=gpnpd,cname=grac4,host=grac41,
pid=4548/gpnpd h:grac41 c:grac4"
The above problem was related to a Name Server problem
==> For further details see GENERIC Networking chapter
Case #2 : Voting Disk is not accessible
In 11gR2, ocssd.bin discover voting disk with setting from GPnP profile, if not enough voting disks can be identified,
ocssd.bin will abort itself.
Reported error in ocssd.log : clssnmvDiskVerify: Successful discovery of 0 disks
Reported Clusterware Error in CW alert.log: CRS-1714:Unable to discover any voting files, retrying discovery in 15 seconds
Testing scenario :
[grid@grac41 ~]$ chmod 000 /dev/asmdisk1_udev_sdf1
[grid@grac41 ~]$ chmod 000 /dev/asmdisk1_udev_sdg1
[grid@grac41 ~]$ chmod 000 /dev/asmdisk1_udev_sdh1
[grid@grac41 ~]$ ls -l /dev/asmdisk1_udev_sdf1 /dev/asmdisk1_udev_sdg1 /dev/asmdisk1_udev_sdh1
b---------. 1 grid asmadmin 8, 81 May 14 09:51 /dev/asmdisk1_udev_sdf1
b---------. 1 grid asmadmin 8, 97 May 14 09:51 /dev/asmdisk1_udev_sdg1
b---------. 1 grid asmadmin 8, 113 May 14 09:51 /dev/asmdisk1_udev_sdh1
Clusterware status :
NAME TARGET STATE SERVER STATE_DETAILS
------------------------- ---------- ---------- ------------ ------------------
ora.asm ONLINE OFFLINE Instance Shutdown
ora.cluster_interconnect.haip ONLINE OFFLINE
ora.crf ONLINE ONLINE grac41
ora.crsd ONLINE OFFLINE
ora.cssd ONLINE OFFLINE STARTING
ora.cssdmonitor ONLINE ONLINE grac41
ora.ctssd ONLINE OFFLINE
ora.diskmon OFFLINE OFFLINE
ora.drivers.acfs ONLINE OFFLINE
ora.evmd ONLINE OFFLINE
ora.gipcd ONLINE ONLINE grac41
ora.gpnpd ONLINE ONLINE grac41
ora.mdnsd ONLINE ONLINE grac41
--> cssd is STARTING mode for a long time before switching to OFFLINE
# ps -elf | egrep "PID|d.bin|ohas|oraagent|orarootagent|cssdagent|cssdmonitor" | grep -v grep
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 6098 1 0 80 0 - 2846 pipe_w 04:44 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run
4 R root 31696 1 4 80 0 - 179039 - 07:59 ? 00:00:06 /u01/app/11204/grid/bin/ohasd.bin reboot
4 S grid 31825 1 0 80 0 - 169311 futex_ 07:59 ? 00:00:00 /u01/app/11204/grid/bin/oraagent.bin
0 S grid 31836 1 0 80 0 - 74289 poll_s 07:59 ? 00:00:00 /u01/app/11204/grid/bin/mdnsd.bin
0 S grid 31847 1 0 80 0 - 127382 hrtime 07:59 ? 00:00:00 /u01/app/11204/grid/bin/gpnpd.bin
0 S grid 31859 1 2 80 0 - 159711 hrtime 07:59 ? 00:00:03 /u01/app/11204/grid/bin/gipcd.bin
4 S root 31861 1 0 80 0 - 165832 futex_ 07:59 ? 00:00:00 /u01/app/11204/grid/bin/orarootagent.bin
4 S root 31875 1 5 -40 - - 160907 hrtime 07:59 ? 00:00:08 /u01/app/11204/grid/bin/osysmond.bin
4 S root 31934 1 0 -40 - - 162468 futex_ 07:59 ? 00:00:00 /u01/app/11204/grid/bin/cssdmonitor
4 S root 31953 1 0 -40 - - 161056 futex_ 07:59 ? 00:00:00 /u01/app/11204/grid/bin/cssdagent
4 S grid 31965 1 0 -40 - - 109118 futex_ 07:59 ? 00:00:00 /u01/app/11204/grid/bin/ocssd.bin
4 S root 32201 1 0 -40 - - 161632 poll_s 07:59 ? 00:00:01 /u01/app/11204/grid/bin/ologgerd -M -d /u01/app/11204/grid/crf/db/grac41
Quick Tracefile Review using grep
$ fn_egrep.sh "Successful discovery"
Working case:
TraceFileName: ./grac41/cssd/ocssd.log
2014-05-22 11:46:57.229: [ CSSD][201324288]clssnmvDiskVerify: Successful discovery for disk /dev/asmdisk1_udev_sdg1,
UID 88c2a08b-4c8c4f85-bf0109e0-990388e4, Pending CIN 0:1399993206:1, Committed CIN 0:1399993206:1
2014-05-22 11:46:57.230: [ CSSD][201324288]clssnmvDiskVerify: Successful discovery for disk /dev/asmdisk1_udev_sdf1,
UID b0e94e5d-83054fe9-bf58b6b9-8bfacd65, Pending CIN 0:1399993206:1, Committed CIN 0:1399993206:1
2014-05-22 11:46:57.230: [ CSSD][201324288]clssnmvDiskVerify: Successful discovery for disk /dev/asmdisk1_udev_sdh1,
UID 2121ff6e-acab4f49-bf01195f-a0a3e00b, Pending CIN 0:1399993206:1, Committed CIN 0:1399993206:1
2014-05-22 11:46:57.231: [ CSSD][201324288]clssnmvDiskVerify: Successful discovery of 3 disks
Failed case:
2014-05-22 13:41:38.776: [ CSSD][1839290112]clssnmvDiskVerify: Successful discovery of 0 disks
2014-05-22 13:41:53.803: [ CSSD][1839290112]clssnmvDiskVerify: Successful discovery of 0 disks
2014-05-22 13:42:08.851: [ CSSD][1839290112]clssnmvDiskVerify: Successful discovery of 0 disks
--> disk redicovery is restarted every 15 seconds in case of errors
Tracefile Details:
grid@grac41 grac41]$c d $GRID_HOME/log/grac41 ; get_ca.sh alertgrac41.log "2014-05-24"
2014-05-24 07:59:27.167: [cssd(31965)]CRS-1714:Unable to discover any voting files, retrying discovery in 15 seconds;
Details at (:CSSNM00070:) in /u01/app/11204/grid/log/grac41/cssd/ocssd.log
2014-05-24 07:59:42.197: [cssd(31965)]CRS-1714:Unable to discover any voting files, retrying discovery in 15 seconds;
Details at (:CSSNM00070:) in /u01/app/11204/grid/log/grac41/cssd/ocssd.log
grac41/cssd/ocssd.log
2014-05-24 08:10:14.145: [ SKGFD][268433152]Lib :UFS:: closing handle 0x7fa3041525a0 for disk :/dev/asmdisk1_udev_sdb1:
2014-05-24 08:10:14.145: [ SKGFD][268433152]Lib :UFS:: closing handle 0x7fa304153050 for disk :/dev/asmdisk8_ssd3:
2014-05-24 08:10:14.145: [ SKGFD][268433152]Lib :UFS:: closing handle 0x7fa304153c70 for disk :/dev/oracleasm/disks/ASMLIB_DISK1:
2014-05-24 08:10:14.145: [ SKGFD][268433152]Lib :UFS:: closing handle 0x7fa304154ac0 for disk :/dev/oracleasm/disks/ASMLIB_DISK2:
2014-05-24 08:10:14.145: [ SKGFD][268433152]Lib :UFS:: closing handle 0x7fa304155570 for disk :/dev/oracleasm/disks/ASMLIB_DISK3:
2014-05-24 08:10:14.145: [ CSSD][268433152]clssnmvDiskVerify: Successful discovery of 0 disks
2014-05-24 08:10:14.145: [ CSSD][268433152]clssnmvDiskVerify: exit
2014-05-24 08:10:14.145: [ CSSD][268433152]clssnmCompleteInitVFDiscovery: Completing initial voting file discovery
2014-05-24 08:10:14.145: [ CSSD][268433152]clssnmvFindInitialConfigs: No voting files found
Debugging steps with cluvfy
Note you must run cluvfy from a node which is up and running as we need ASM to retrieve Voting Disk location
Here we are ruuning cluvfy from grac42 to test voting disks on grac41
[grid@grac42 ~]$ cluvfy comp vdisk -n grac41
Verifying Voting Disk:
Checking Oracle Cluster Voting Disk configuration...
ERROR:
PRVF-4194 : Asm is not running on any of the nodes. Verification cannot proceed.
ERROR:
PRVF-5157 : Could not verify ASM group "OCR" for Voting Disk location "/dev/asmdisk1_udev_sdf1"
ERROR:
PRVF-5157 : Could not verify ASM group "OCR" for Voting Disk location "/dev/asmdisk1_udev_sdg1"
ERROR:
PRVF-5157 : Could not verify ASM group "OCR" for Voting Disk location "/dev/asmdisk1_udev_sdh1"
PRVF-5431 : Oracle Cluster Voting Disk configuration check failed
UDev attributes check for Voting Disk locations started...
UDev attributes check passed for Voting Disk locations
Verification of Voting Disk was unsuccessful on all the specified nodes.
Verify disk protections by using kfed and ls
[grid@grac41 ~/cluvfy]$ ls -l /dev/asmdisk1_udev_sdf1 /dev/asmdisk1_udev_sdg1 /dev/asmdisk1_udev_sdh1
b---------. 1 grid asmadmin 8, 81 May 14 09:51 /dev/asmdisk1_udev_sdf1
b---------. 1 grid asmadmin 8, 97 May 14 09:51 /dev/asmdisk1_udev_sdg1
b---------. 1 grid asmadmin 8, 113 May 14 09:51 /dev/asmdisk1_udev_sdh1
[grid@grac41 ~/cluvfy]$ kfed read /dev/asmdisk1_udev_sdf1
KFED-00303: unable to open file '/dev/asmdisk1_udev_sdf
Case #3 : GENERIC NETWORK problems
==> For futher details see GENERIC Networking chapter
ASM instance does not start / EVMD.BIN in State INTERMEDIATE
Reported error in oraagent_grid.log : CRS-5017: The resource action "ora.asm start" encountered the following error:
ORA-12546: TNS:permission denied
Reported Clusterware Error in CW alert.log: [/u01/app/11204/grid/bin/oraagent.bin(6784)]CRS-5011:Check of resource "+ASM" failed:
[ohasd(6536)]CRS-2807:Resource 'ora.asm' failed to start automatically.
Reported Error in ASM alert log : ORA-07274: spdcr: access error, access to oracle denied.
Linux-x86_64 Error: 13: Permission denied
PSP0 (ospid: 3582): terminating the instance due to error 7274
...
Testing scenario :
[grid@grac41 grac41]$ cd $GRID_HOME/bin
[grid@grac41 bin]$ chmod 444 oracle
[grid@grac41 bin]$ ls -l oracle
-r--r--r--. 1 grid oinstall 209950863 May 4 10:26 oracle
# crsctl start crs
CRS-4123: Oracle High Availability Services has been started.
Clusterware status :
[grid@grac41 bin]$ crsctl check crs
CRS-4638: Oracle High Availability Services is online
CRS-4535: Cannot communicate with Cluster Ready Services
CRS-4529: Cluster Synchronization Services is online
CRS-4534: Cannot communicate with Event Manager
[grid@grac41 bin]$ crsi
NAME TARGET STATE SERVER STATE_DETAILS
------------------------- ---------- ---------- ------------ ------------------
ora.asm ONLINE OFFLINE
ora.cluster_interconnect.haip ONLINE ONLINE grac41
ora.crf ONLINE ONLINE grac41
ora.crsd ONLINE OFFLINE
ora.cssd ONLINE ONLINE grac41
ora.cssdmonitor ONLINE ONLINE grac41
ora.ctssd ONLINE ONLINE grac41 OBSERVER
ora.diskmon OFFLINE OFFLINE
ora.drivers.acfs ONLINE ONLINE grac41
ora.evmd ONLINE INTERMEDIATE grac41
ora.gipcd ONLINE ONLINE grac41
ora.gpnpd ONLINE ONLINE grac41
ora.mdnsd ONLINE ONLINE grac41
[grid@grac41 bin]$ ps -elf | egrep "PID|d.bin|ohas|oraagent|orarootagent|cssdagent|cssdmonitor" | grep -v grep
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 3408 28369 0 80 0 - 30896 poll_s 10:03 pts/3 00:00:00 view ./agent/crsd/oraagent_grid/oraagent_grid.log
4 S root 6098 1 0 80 0 - 2846 pipe_w May24 ? 00:00:01 /bin/sh /etc/init.d/init.ohasd run
4 S root 6536 1 2 80 0 - 179140 futex_ 13:51 ? 00:01:11 /u01/app/11204/grid/bin/ohasd.bin reboot
4 S grid 6784 1 0 80 0 - 173902 futex_ 13:52 ? 00:00:05 /u01/app/11204/grid/bin/oraagent.bin
0 S grid 6795 1 0 80 0 - 74289 poll_s 13:52 ? 00:00:00 /u01/app/11204/grid/bin/mdnsd.bin
0 S grid 6806 1 0 80 0 - 127382 hrtime 13:52 ? 00:00:04 /u01/app/11204/grid/bin/gpnpd.bin
0 S grid 6823 1 1 80 0 - 159711 hrtime 13:52 ? 00:00:39 /u01/app/11204/grid/bin/gipcd.bin
4 S root 6825 1 0 80 0 - 168698 futex_ 13:52 ? 00:00:24 /u01/app/11204/grid/bin/orarootagent.bin
4 S root 6840 1 4 -40 - - 160907 hrtime 13:52 ? 00:02:29 /u01/app/11204/grid/bin/osysmond.bin
4 S root 6851 1 0 -40 - - 162793 futex_ 13:52 ? 00:00:07 /u01/app/11204/grid/bin/cssdmonitor
4 S root 6870 1 0 -40 - - 162920 futex_ 13:52 ? 00:00:07 /u01/app/11204/grid/bin/cssdagent
4 S grid 6881 1 2 -40 - - 166593 futex_ 13:52 ? 00:01:24 /u01/app/11204/grid/bin/ocssd.bin
4 S root 7256 1 6 -40 - - 178527 poll_s 13:52 ? 00:03:28 /u01/app/11204/grid/bin/ologgerd -M -d ..
4 S root 7847 1 0 80 0 - 159388 futex_ 13:52 ? 00:00:29 /u01/app/11204/grid/bin/octssd.bin reboot
0 S grid 7875 1 0 80 0 - 76018 hrtime 13:52 ? 00:00:05 /u01/app/11204/grid/bin/evmd.bin
Tracefile Details:
CW alert.log
[/u01/app/11204/grid/bin/oraagent.bin(6784)]CRS-5011:Check of resource "+ASM" failed:
details at "(:CLSN00006:)" in "../agent/ohasd/oraagent_grid/oraagent_grid.log"
[/u01/app/11204/grid/bin/oraagent.bin(6784)]CRS-5011:Check of resource "+ASM" failed:
details at "(:CLSN00006:)" in "../agent/ohasd/oraagent_grid/oraagent_grid.log"
2014-05-25 13:55:04.626: [ohasd(6536)]CRS-2807:Resource 'ora.asm' failed to start automatically.
2014-05-25 13:55:04.626: [ohasd(6536)]CRS-2807:Resource 'ora.crsd' failed to start automatically.
ASM alert log : ./log/diag/asm/+asm/+ASM1/trace/alert_+ASM1.log
Sun May 25 13:50:50 2014
Errors in file /u01/app/11204/grid/log/diag/asm/+asm/+ASM1/trace/+ASM1_psp0_3582.trc:
ORA-07274: spdcr: access error, access to oracle denied.
Linux-x86_64 Error: 13: Permission denied
PSP0 (ospid: 3582): terminating the instance due to error 7274
Sun May 25 13:50:50 2014
System state dump requested by (instance=1, osid=3591 (DIAG)), summary=[abnormal instance termination].
System State dumped to trace file /u01/app/11204/grid/log/diag/asm/+asm/+ASM1/trace/+ASM1_diag_3591_20140525135050.trc
Dumping diagnostic data in directory=[cdmp_20140525135050], requested by (instance=1, osid=3591 (DIAG)),
summary=[abnormal instance termination].
Instance terminated by PSP0, pid = 3582
agent/ohasd/oraagent_grid/oraagent_grid.log
2014-05-25 13:54:54.226: [ AGFW][3273144064]{0:0:2} ora.asm 1 1 state changed from: STARTING to: OFFLINE
2014-05-25 13:54:54.229: [ AGFW][3273144064]{0:0:2} Agent sending last reply for: RESOURCE_START[ora.asm 1 1] ID 4098:624
2014-05-25 13:54:54.239: [ AGFW][3273144064]{0:0:2} Agent received the message: RESOURCE_CLEAN[ora.asm 1 1] ID 4100:644
2014-05-25 13:54:54.239: [ AGFW][3273144064]{0:0:2} Preparing CLEAN command for: ora.asm 1 1
2014-05-25 13:54:54.239: [ AGFW][3273144064]{0:0:2} ora.asm 1 1 state changed from: OFFLINE to: CLEANING
Debugging steps :
Try to start ASM databbase manually
[grid@grac41 grid]$ sqlplus / as sysasm
ERROR:
ORA-12546: TNS:permission denied
Fix:
[grid@grac41 grid]$ chmod 6751 $GRID_HOME/bin/oracle
[grid@grac41 grid]$ ls -l $GRID_HOME/bin/oracle
-rwsr-s--x. 1 grid oinstall 209950863 May 4 10:26 /u01/app/11204/grid/bin/oracle
[grid@grac41 grid]$ sqlplus / as sysasm
--> works now again
EVMD.BIN does not start : State INTERMEDIATE
==> For further details see GENERIC Networking troubleshooting chapter
CRSD.BIN does not start
-
-
- Note: in 11.2 ASM starts before crsd.bin, and brings up the diskgroup automatically if it contains the OCR.
- Typical Problems :
- OCR not acessible
- Networking problems ( includes firewall, Nameserver problems and Network related errors ) ==> For futher details see GENERIC Networking troubleshooting chapter
- Common File Protection problems ( Oracle executable, Log Files, IPC sockets ) ==> For futher details see GENERIC File Protection troubleshooting chapter
Case #1: OCR not accessbible - CRS-5019 error
Reported error in ocssd.log : [check] DgpAgent::queryDgStatus no data found in v$asm_diskgroup_stat
Reported Clusterware Error in CW alert.log: CRS-5019:All OCR locations are on ASM disk groups [OCR3],
and none of these disk groups are mounted.
Details are at "(:CLSN00100:)" in ".../ohasd/oraagent_grid/oraagent_grid.log".
Testing scenario :
In file /etc/oracle/ocr.loc
Change entry ocrconfig_loc=+OCR to ocrconfig_loc=+OCR3
Clusterware status :
# crsctl check crs
CRS-4638: Oracle High Availability Services is online
CRS-4535: Cannot communicate with Cluster Ready Services
CRS-4529: Cluster Synchronization Services is online
CRS-4534: Cannot communicate with Event Manager
# crsi
NAME TARGET STATE SERVER STATE_DETAILS
------------------------- ---------- ---------- ------------ ------------------
ora.asm ONLINE INTERMEDIATE grac41 OCR not started
ora.cluster_interconnect.haip ONLINE ONLINE grac41
ora.crf ONLINE ONLINE grac41
ora.crsd ONLINE OFFLINE
ora.cssd ONLINE ONLINE grac41
ora.cssdmonitor ONLINE ONLINE grac41
ora.ctssd ONLINE ONLINE grac41 OBSERVER
ora.diskmon OFFLINE OFFLINE
ora.drivers.acfs ONLINE ONLINE grac41
ora.evmd ONLINE INTERMEDIATE grac41
ora.gipcd ONLINE ONLINE grac41
ora.gpnpd ONLINE ONLINE grac41
ora.mdnsd ONLINE ONLINE grac41
--> Both resoruces ora.evmd and ora.asm reports their state in INTERMEDIATE - CRSD/EVMD doesn't come up
# ps -elf | egrep "PID|d.bin|ohas|oraagent|orarootagent|cssdagent|cssdmonitor" | grep -v grep
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 6098 1 0 80 0 - 2846 pipe_w 04:44 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run
4 S root 10132 1 1 80 0 - 179077 futex_ 10:09 ? 00:00:07 /u01/app/11204/grid/bin/ohasd.bin reboot
4 S grid 10295 1 0 80 0 - 175970 futex_ 10:09 ? 00:00:03 /u01/app/11204/grid/bin/oraagent.bin
0 S grid 10306 1 0 80 0 - 74289 poll_s 10:09 ? 00:00:00 /u01/app/11204/grid/bin/mdnsd.bin
0 S grid 10317 1 0 80 0 - 127382 hrtime 10:09 ? 00:00:01 /u01/app/11204/grid/bin/gpnpd.bin
0 S grid 10328 1 1 80 0 - 159711 hrtime 10:09 ? 00:00:04 /u01/app/11204/grid/bin/gipcd.bin
4 S root 10330 1 1 80 0 - 168735 futex_ 10:09 ? 00:00:04 /u01/app/11204/grid/bin/orarootagent.bin
4 S root 10344 1 6 -40 - - 160907 hrtime 10:09 ? 00:00:25 /u01/app/11204/grid/bin/osysmond.bin
4 S root 10355 1 0 -40 - - 162793 futex_ 10:09 ? 00:00:01 /u01/app/11204/grid/bin/cssdmonitor
4 S root 10374 1 0 -40 - - 162921 futex_ 10:09 ? 00:00:01 /u01/app/11204/grid/bin/cssdagent
4 S grid 10385 1 4 -40 - - 166593 futex_ 10:09 ? 00:00:17 /u01/app/11204/grid/bin/ocssd.bin
4 S root 10733 1 0 -40 - - 127270 poll_s 10:09 ? 00:00:03 /u01/app/11204/grid/bin/ologgerd
4 S root 11286 1 0 80 0 - 159388 futex_ 10:09 ? 00:00:03 /u01/app/11204/grid/bin/octssd.bin reboot
0 S grid 11307 1 0 80 0 - 75351 hrtime 10:09 ? 00:00:00 /u01/app/11204/grid/bin/evmd.bin
Tracefile Details :
alertgrac41.log:
2014-05-24 10:13:48.085:
[/u01/app/11204/grid/bin/oraagent.bin(10295)]CRS-5019:All OCR locations are on ASM disk groups [OCR3],
and none of these disk groups are mounted.
Details are at "(:CLSN00100:)" in ".../agent/ohasd/oraagent_grid/oraagent_grid.log".
2014-05-24 10:14:18.144:
[/u01/app/11204/grid/bin/oraagent.bin(10295)]CRS-5019:All OCR locations are on ASM disk groups [OCR3],
and none of these disk groups are mounted.
Details are at "(:CLSN00100:)" in ".../agent/ohasd/oraagent_grid/oraagent_grid.log".
ohasd/oraagent_grid/oraagent_grid.log
2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] AsmAgent::check ocrCheck 1 m_OcrOnline 0 m_OcrTimer 30
2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::initOcrDgpSet { entry
2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::initOcrDgpSet procr_get_conf: retval [0]
configured [1] local only [0] error buffer []
2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::initOcrDgpSet procr_get_conf: OCR loc [0], Disk Group : [+OCR3]
2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::initOcrDgpSet m_ocrDgpSet 02d965f8 dgName OCR3
2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::initOcrDgpSet ocrret 0 found 1
2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::initOcrDgpSet ocrDgpSet OCR3
2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::initOcrDgpSet exit }
2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::ocrDgCheck Entry {
2014-05-24 10:10:47.848: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::getConnxn connected
2014-05-24 10:10:47.850: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::queryDgStatus excp no data found
2014-05-24 10:10:47.850: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::queryDgStatus no data found in v$asm_diskgroup_stat
2014-05-24 10:10:47.851: [ora.asm][4179105536]{0:0:2} [check] DgpAgent::queryDgStatus dgName OCR3 ret 1
2014-05-24 10:10:47.851: [ora.asm][4179105536]{0:0:2} [check] (:CLSN00100:)DgpAgent::ocrDgCheck OCR dgName OCR3 state 1
2014-05-24 10:10:47.851: [ora.asm][4179105536]{0:0:2} [check] AsmAgent::check ocrCheck 2 m_OcrOnline 0 m_OcrTimer 31
2014-05-24 10:10:47.851: [ora.asm][4179105536]{0:0:2} [check] CrsCmd::ClscrsCmdData::stat entity 5 statflag 32 useFilter 1
2014-05-24 10:10:48.053: [ COMMCRS][3665618688]clsc_connect: (0x7f77d4101f30) no listener at (ADDRESS=(PROTOCOL=IPC)(KEY=CRSD_UI_SOCKET))
Debugging steps
Identify OCR ASM DG on a running instance with asmcmd
[grid@grac42 ~]$ asmcmd lsdg
State Type Rebal Sector Block AU Total_MB Offline_disks Voting_files Name
MOUNTED NORMAL N 512 4096 1048576 3057 0 N ASMLIB_DG/
MOUNTED NORMAL N 512 4096 1048576 30708 0 N DATA/
MOUNTED EXTERN N 512 4096 1048576 40946 0 N FRA/
MOUNTED NORMAL N 512 4096 1048576 6141 0 Y OCR/
MOUNTED NORMAL N 512 4096 1048576 3057 0 N SSD/
--> diskgroup OCR is serving our voting disks ( and not DG +OCR3 )
Check availale disks:
[grid@grac42 ~]$ asmcmd lsdsk -k
Total_MB Free_MB OS_MB Name Failgroup Failgroup_Type Library Path
10236 2809 10236 DATA_0001 DATA_0001 REGULAR System /dev/asmdisk1_udev_sdc1
10236 2804 10236 DATA_0002 DATA_0002 REGULAR System /dev/asmdisk1_udev_sdd1
10236 2804 10236 DATA_0003 DATA_0003 REGULAR System /dev/asmdisk1_udev_sde1
2047 1696 2047 OCR_0000 OCR_0000 REGULAR System /dev/asmdisk1_udev_sdf1
2047 1696 2047 OCR_0001 OCR_0001 REGULAR System /dev/asmdisk1_udev_sdg1
2047 1697 2047 OCR_0002 OCR_0002 REGULAR System /dev/asmdisk1_udev_sdh1
1019 875 1019 SSD_0000 SSD_0000 REGULAR System /dev/asmdisk8_ssd1
1019 875 1019 SSD_0001 SSD_0001 REGULAR System /dev/asmdisk8_ssd2
1019 875 1019 SSD_0002 SSD_0002 REGULAR System /dev/asmdisk8_ssd3
20473 10467 20473 FRA_0001 FRA_0001 REGULAR System /dev/asmdisk_fra1
20473 10461 20473 FRA_0002 FRA_0002 REGULAR System /dev/asmdisk_fra2
1019 882 1019 ASMLIB_DG_0000 ASMLIB_DG_0000 REGULAR System /dev/oracleasm/disks/ASMLIB_DISK1
1019 882 1019 ASMLIB_DG_0001 ASMLIB_DG_0001 REGULAR System /dev/oracleasm/disks/ASMLIB_DISK2
1019 882 1019 ASMLIB_DG_0002 ASMLIB_DG_0002 REGULAR System /dev/oracleasm/disks/ASMLIB_DISK3
--> /dev/asmdisk1_udev_sdf1, /dev/asmdisk1_udev_sdg1 , /dev/asmdisk1_udev_sdh1 are
our disk serving the voting files
Verify on a working system the voting disk
[grid@grac42 ~]$ kfed read /dev/asmdisk1_udev_sdf1 | egrep 'vf|name'
kfdhdb.dskname: OCR_0000 ; 0x028: length=8
kfdhdb.grpname: OCR ; 0x048: length=3
kfdhdb.fgname: OCR_0000 ; 0x068: length=8
kfdhdb.capname: ; 0x088: length=0
kfdhdb.vfstart: 320 ; 0x0ec: 0x00000140
kfdhdb.vfend: 352 ; 0x0f0: 0x00000160
Note: If the markers between vfstart & vfend are not 0 then disk does contain voting disk !
Check OCR with ocrcheck
[grid@grac41 ~]$ ocrcheck
PROT-602: Failed to retrieve data from the cluster registry
PROC-26: Error while accessing the physical storage
Tracing ocrcheck
[grid@grac41 ~]$ strace -f -o ocrcheck.trc ocrcheck
[grid@grac41 ~]$ grep open ocrcheck.trc | grep ocr.loc
17530 open("/etc/oracle/ocr.loc", O_RDONLY) = 6
--> ocrcheck reads /etc/oracle/ocr.loc
[grid@grac41 ~]$ cat /etc/oracle/ocr.loc
ocrconfig_loc=+OCR3
local_only=false
==> +OCR3 is a wrong entry
Verify CW state with cluvfy
[grid@grac42 ~]$ cluvfy comp ocr -n grac42,grac41
Verifying OCR integrity
Checking OCR integrity...
Checking the absence of a non-clustered configuration...
All nodes free of non-clustered, local-only configurations
ERROR:
PRVF-4193 : Asm is not running on the following nodes.
Proceeding with the remaining nodes.
grac41
Checking OCR config file "/etc/oracle/ocr.loc"...
OCR config file "/etc/oracle/ocr.loc" check successful
ERROR:
PRVF-4195 : Disk group for ocr location "+OCR" not available on the following nodes:
grac41
NOTE:
This check does not verify the integrity of the OCR contents.
Execute 'ocrcheck' as a privileged user to verify the contents of OCR.
OCR integrity check failed
Verification of OCR integrity was unsuccessful.
Checks did not pass for the following node(s):
grac41
Some agents of the OHASD stack like mdnsd.bin, gpnpd.bin or gipcd.bin are not starting up
Case 1 : Wrong protection for executable $GRID_HOME/bin/gpnpd.bin
==> For add. details see GENERIC File Protection chapter
Reported error in oraagent_grid.log : [ clsdmc][1103787776]Fail to connect (ADDRESS=(PROTOCOL=ipc)
(KEY=grac41DBG_GPNPD)) with status 9
[ora.gpnpd][1103787776]{0:0:2} [start] Error = error 9 encountered
when connecting to GPNPD
Reported Clusterware Error in CW alert.log: [/u01/app/11204/grid/bin/oraagent.bin(20333)]
CRS-5818:Aborted command 'start' for resource 'ora.gpnpd'.
Details at (:CRSAGF00113:) {0:0:2} in ..... ohasd/oraagent_grid/oraagent_grid.log
Testing scenario :
[grid@grac41 ~]$ chmod 444 $GRID_HOME/bin/gpnpd.bin
[grid@grac41 ~]$ ls -l $GRID_HOME/bin/gpnpd.bin
-r--r--r--. 1 grid oinstall 368780 Mar 19 17:07 /u01/app/11204/grid/bin/gpnpd.bin
[root@grac41 gpnp]# crsctl start crs
CRS-4123: Oracle High Availability Services has been started.
Clusterware status :
$ crsctl check crs
CRS-4638: Oracle High Availability Services is online
CRS-4535: Cannot communicate with Cluster Ready Services
CRS-4530: Communications failure contacting Cluster Synchronization Services daemon
CRS-4534: Cannot communicate with Event Manager
$ crsi
NAME TARGET STATE SERVER STATE_DETAILS
------------------------- ---------- ---------- ------------ ------------------
ora.asm ONLINE OFFLINE Instance Shutdown
ora.cluster_interconnect.haip ONLINE OFFLINE
ora.crf ONLINE OFFLINE
ora.crsd ONLINE OFFLINE
ora.cssd ONLINE OFFLINE
ora.cssdmonitor OFFLINE OFFLINE
ora.ctssd ONLINE OFFLINE
ora.diskmon OFFLINE OFFLINE
ora.drivers.acfs ONLINE OFFLINE
ora.evmd ONLINE OFFLINE
ora.gipcd ONLINE OFFLINE
ora.gpnpd ONLINE OFFLINE STARTING
ora.mdnsd ONLINE ONLINE grac41
--> GPnP deamon remains ins starting Mode
$ ps -elf | egrep "PID|d.bin|ohas" | grep -v grep
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 6098 1 0 80 0 - 2846 pipe_w 04:44 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run
4 S root 20127 1 23 80 0 - 176890 futex_ 11:52 ? 00:00:51 /u01/app/11204/grid/bin/ohasd.bin reboot
4 S grid 20333 1 0 80 0 - 166464 futex_ 11:52 ? 00:00:02 /u01/app/11204/grid/bin/oraagent.bin
0 S grid 20344 1 0 80 0 - 74289 poll_s 11:52 ? 00:00:00 /u01/app/11204/grid/bin/mdnsd.bin
Review Tracefile :
alertgrac41.log
[/u01/app/11204/grid/bin/oraagent.bin(27632)]CRS-5818:Aborted command 'start' for resource 'ora.gpnpd'.
Details at (:CRSAGF00113:) {0:0:2} in ... agent/ohasd/oraagent_grid/oraagent_grid.log.
2014-05-12 10:27:51.747:
[ohasd(27477)]CRS-2757:Command 'Start' timed out waiting for response from the resource 'ora.gpnpd'.
Details at (:CRSPE00111:) {0:0:2} in /u01/app/11204/grid/log/grac41/ohasd/ohasd.log
oraagent_grid.log
[ clsdmc][1103787776]Fail to connect (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_GPNPD)) with status 9
2014-05-12 10:27:17.476: [ora.gpnpd][1103787776]{0:0:2} [start] Error = error 9 encountered when connecting to GPNPD
2014-05-12 10:27:18.477: [ora.gpnpd][1103787776]{0:0:2} [start] without returnbuf
2014-05-12 10:27:18.659: [ COMMCRS][1125422848]clsc_connect: (0x7f3b300d92d0) no listener at (ADDRESS=(PROTOCOL=ipc)(KEY=grac41DBG_GPNPD))
ohasd.log
2014-05-12 10:27:51.745: [ AGFW][2693531392]{0:0:2} Received the reply to the message: RESOURCE_START[ora.gpnpd 1 1] ID 4098:362 from
the agent /u01/app/11204/grid/bin/oraagent_grid
2014-05-12 10:27:51.745: [ AGFW][2693531392]{0:0:2} Agfw Proxy Server sending the reply to PE for message:
RESOURCE_START[ora.gpnpd 1 1] ID 4098:361
2014-05-12 10:27:51.747: [ CRSPE][2212488960]{0:0:2} Received reply to action [Start] message ID: 361
2014-05-12 10:27:51.747: [ INIT][2212488960]{0:0:2} {0:0:2} Created alert : (:CRSPE00111:) : Start action timed out!
2014-05-12 10:27:51.747: [ CRSPE][2212488960]{0:0:2} Start action failed with error code: 3
2014-05-12 10:27:52.123: [ AGFW][2693531392]{0:0:2} Received the reply to the message: RESOURCE_START[ora.gpnpd 1 1] ID 4098:362 from the
agent /u01/app/11204/grid/bin/oraagent_grid
2014-05-12 10:27:52.123: [ AGFW][2693531392]{0:0:2} Agfw Proxy Server sending the last reply to PE for message:
RESOURCE_START[ora.gpnpd 1 1] ID 4098:361
2014-05-12 10:27:52.123: [ CRSPE][2212488960]{0:0:2} Received reply to action [Start] message ID: 361
2014-05-12 10:27:52.123: [ CRSPE][2212488960]{0:0:2} RI [ora.gpnpd 1 1] new internal state: [STABLE] old value: [STARTING]
2014-05-12 10:27:52.123: [ CRSPE][2212488960]{0:0:2} CRS-2674: Start of 'ora.gpnpd' on 'grac41' failed
--> Here we see that are failing to start GPnP resource
Debugging steps :
Is process gpnpd.bin running ?
[root@grac41 ~]# ps -elf | egrep "PID|gpnpd" | grep -v grep
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
--> Missing process gpnpd.bin
Restart CRS with strace support
# crsctl stop crs -f
# strace -t -f -o crs_startup.trc crsctl start crs
Check for EACESS erros and check return values of execve() and aceess() sytem calls :
[root@grac41 oracle]# grep EACCES crs_startup.trc
28301 12:19:46 access("/u01/app/11204/grid/bin/gpnpd.bin", X_OK) = -1 EACCES (Permission denied)
Review crs_startup.trc more in detail
27345 12:15:35 execve("/u01/app/11204/grid/bin/gpnpd.bin", ["/u01/app/11204/grid/bin/gpnpd.bi"...], [/* 73 vars */] <unfinished ...>
27238 12:15:35 <... lseek resumed> ) = 164864
27345 12:15:35 <... execve resumed> ) = -1 EACCES (Permission denied)
27345 12:15:35 access("/u01/app/11204/grid/bin/gpnpd.bin", X_OK <unfinished ...>
27238 12:15:35 <... read resumed> "\25\23\"\1\23\3\t\t\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 256) = 256
27345 12:15:35 <... access resumed> ) = -1 EACCES (Permission denied)
Verify problem with cluvfy
[grid@grac41 ~]$ cluvfy comp software -verbose
Verifying software
Check: Software
Component: crs
Node Name: grac41
..
Permissions of file "/u01/app/11204/grid/bin/gpnpd.bin" did not match the expected value.
[Expected = "0755" ; Found = "0444"]
/u01/app/11204/grid/bin/gpnptool.bin..."Permissions" did not match reference
..
References